2. NYU Pile Capacity: An Interactive Web Application and Unifying Pile Load Test Database¶
2.1. History¶
Many of the methods in current use for pile design are based on small databases of interpreted load test data. For piles in sand, Nordlund (1963, 1979) developed his method of calculating bearing capacity of piles in cohesionless soils from as few as 41 load tests from eight different test sites. Similarly, for clays, Tomlinson (1957, 1971) employed a small data set of 56 piles to develop his popular Alpha-design method that was based in part on data published by Peck (1958). These methods were adopted by several design standards including, The Canadian Manual on Foundation Engineering (1975), The American Petroleum Institute (API RP 2A, 1989), and FHWA (Hannigan et al., 2016a, 2016b). Due to the dependence of soil behavior upon geography and site-specific circumstances and the use of limited data employed to launch historical foundation design methods, it is possible that many currently practiced methods of pile design, are based on empirical formulas that required gross overgeneralization to develop.
To address this concern, several past geotechnical studies have been undertaken with a focus on the expansion of load test databases in order to improve the methods employed to predict the axial capacity of piles. The first modern effort to organize a database of measured and interpreted pile capacities was performed at the behest of the American Petroleum Institute (API) by Professor Olson and his students at the University of Texas (Dennis and Olson, 1983a, 1983b). This effort led to the development of the popular API RP-2A method for capacity of piles in sand (API, 1989). Later efforts were made to improve on both the size of the database and on its interpretation (Olson and Al-Shafei, 1988; Olson, 1990; Iskander and Olson, 1992; Olson and Iskander, 1994, 1998 and 2009; Olson and Shantz, 2004). Later, FHWA began a parallel effort to develop a Deep Foundation Load Test Database (DFLTD) under the leadership of Carl Ealy (Kalavar and Ealy, 2000). Likewise, several highway departments developed state databases of interpreted pile capacities including Iowa, Illinois, and Louisiana (Roling et al., 2010 and 2011; Tavera et al., 2016; Long and Anderson, 2012). Similarly several small databases have been developed at a number of universities and research centers including the Norwegian Geotechnical Institute (NGI), and at Texas A&M (Briaud et al., 1987; Lacasse, 1988; Paikowsky, 2001).
In a 2013 memorandum, Abu-Hejleh describes the DFLTD as being “outdated” to the point of impossibility of database expansion (Abu-Hejleh, 2013). Abu-Hejleh et al. (2015a) discussed the usefulness of current databases in use in the United States and establishes the suggested minimum data required for load test databases pertaining to Project Data, Subsurface Data at the Load Test Foundation, Test Foundation Data, Load Test Data, and attachment of useful files. The guidelines for developing useful load test databases discussed by Abu-Hejleh et al. were last updated in 2015 (Abu-Hejleh et al., 2015b).
2.2. Original Data Sources¶
Before discussing database design and data transformations, it is important to describe the original data sources: (1) Dr. Olson’s APC Database, (2) the Iowa PILOT Database, (3) the FHWA DFLTD v.2 and (4) LTRC LAPLTD. Despite the author’s best efforts to coordinate with project owners and contractors in order to collect data, there was little to no interest from the private sector to share data.
2.2.1. Olson APC Database¶
Note
“APC” stands for “Axial Pile Capacity”. There is some confusion that Dr. Olson’s database is called the “API Database”. That is not the case.
2.2.1.1. Background¶
Dr. Roy E. Olson (UT Austin), began development on a pile load test database in 1980, as part of a research project with the American Petroleum Institute (API). API was interested in determining how well their recommended practice design method of the time (API RP-2A, 1980) would compare with actual pile load tests. Significant contributions were made by Norm Dennis who did his Ph.D. dissertation on this project (Dennis, 1982) with the final report submitted to API that year.
Work on the then “API Database” continued between 1984 and 1993 with support from small grants from API, Exxon and Aramco but primarily due to Dr. Olson’s personal involvement and contributions. There were several questions, including, (1) how well different methods of soil strength measurement compared with each other in affecting capacity, (2) predictions of pile settlement under axial load, (3) capacities of steel pipe piles in sand and clay, (4) use of the T-Z method to try to predict pile movements under cyclic axial loading. Answering these questions led to M.S. theses written by the students working on them (Aschenbrenner, 1984; Alyahyai, 1987; Al-Shafei, 1987; Van Go, 1990; Chiu, 1993).
In 1998, Dr. Olson started working on a major research project from the California Department of Transportation (CalTrans). The goal was to develop a new, separate database for CalTrans. The purpose of the CalTrans projects was to conduct soil borings next to existing load tested piles and use this better data to predict pile capacities. It is not clear if the APC database eventually included data from CalTrans.
The original project with API was meant to focus on open-ended steel pipe piles frequently used for offshore structures. However, Dr. Olson expanded the scope to include all pile types and capacity ranges. Information on piles, subsurface conditions and load tests was collected from the literature, DOTs and the Army Corps of Engineers. However, collection was never straightforward. Several governmental agencies, consulting firms and oil companies did not cooperate.
Norm Dennis and Dr. Olson looked at data for about 7,000 load tests but could use data for only about 1,000 of them. The lost data were almost always because: (1) the test was not carried even close to failure, or (2) no soil data were available. Of the 1,000 “usable” cases, there was still a lot of information that needed to be corrected. Indicative of the complexity of the problem of producing reliable data for analysis is the fact that Dr. Olson and his students went through each case four or five times and would always find errors or areas to improve. A list of issues identified by Dr. Olson is presented in Appendix A.1. It is surprising, on several levels, that the challenges Dr. Olson faced when developing the pile load test database almost 40 years ago, are still prevalent today.
2.2.1.2. Database Statistics¶
The Olson APC Database contained 939 distinct load test records of primarily driven and also some cast-in-place concrete and raymond piles. Other pile types were steel pipe, timber, H-Pile, and concrete piles. Distribution of pile types is shown in Fig. 2.1. The majority of the tests were in compression (829 count).
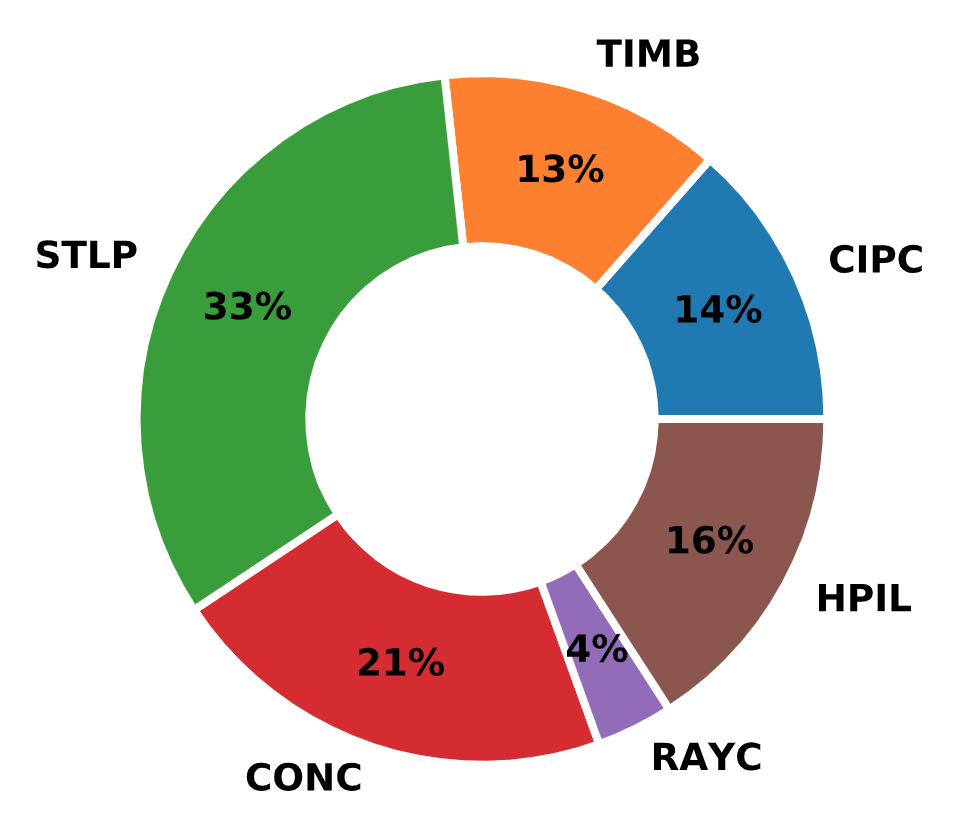
Fig. 2.1 Distribution of Pile Types in the Olson APC Database¶
The average diameter was 16.3 inches with a range from 4.5 to 60 inches. Fig. 2.2 presents a histogram of pile diameters in the Olson APC Database. In terms of pile length, the average value was 72 feet with a range from 8.8 to 370 feet. Fig. 2.3 presents a histogram of pile lengths.
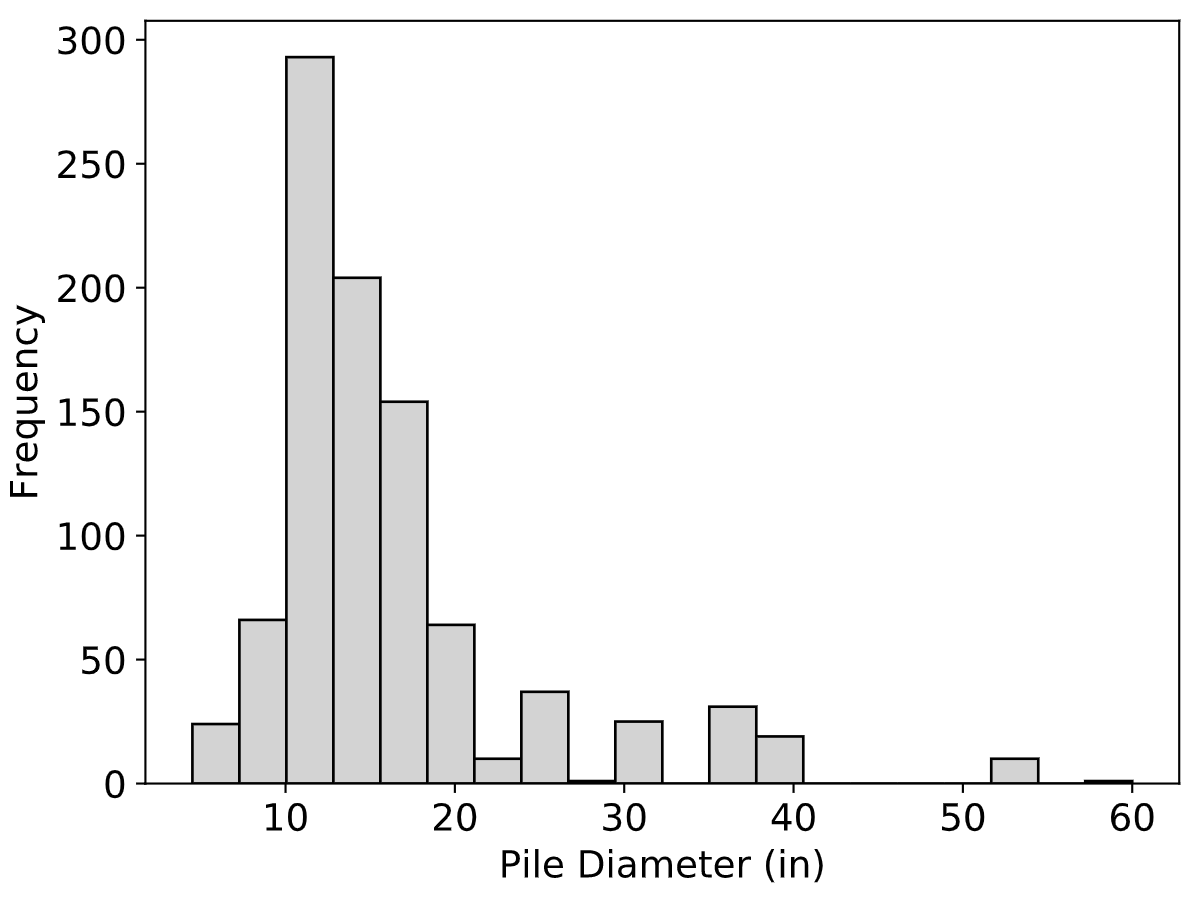
Fig. 2.2 Distribution of Pile Diameters in the Olson APC Database¶
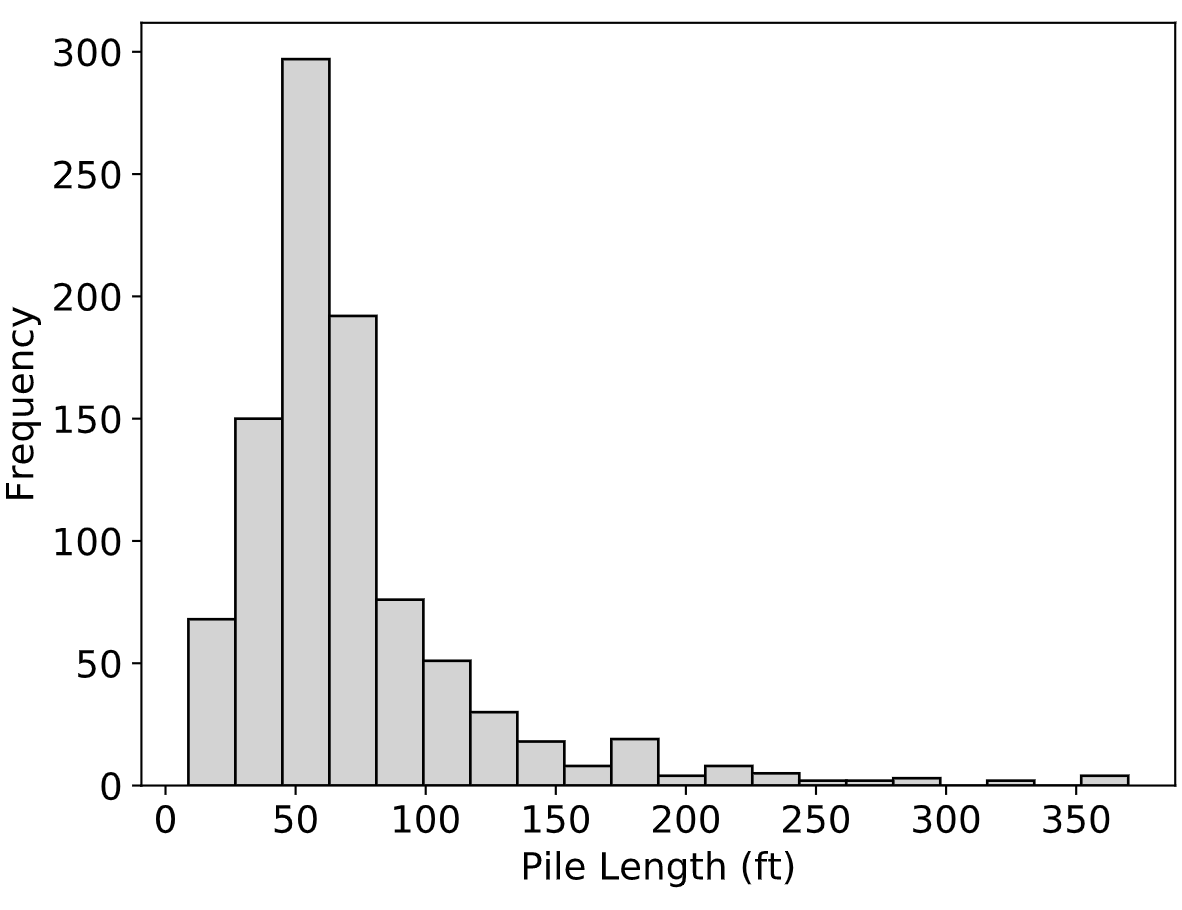
Fig. 2.3 Distribution of Pile Lengths in the Olson APC Database¶
The majority of the piles were constructed in clayey and silty soils, as can be seen in Fig. 2.4.
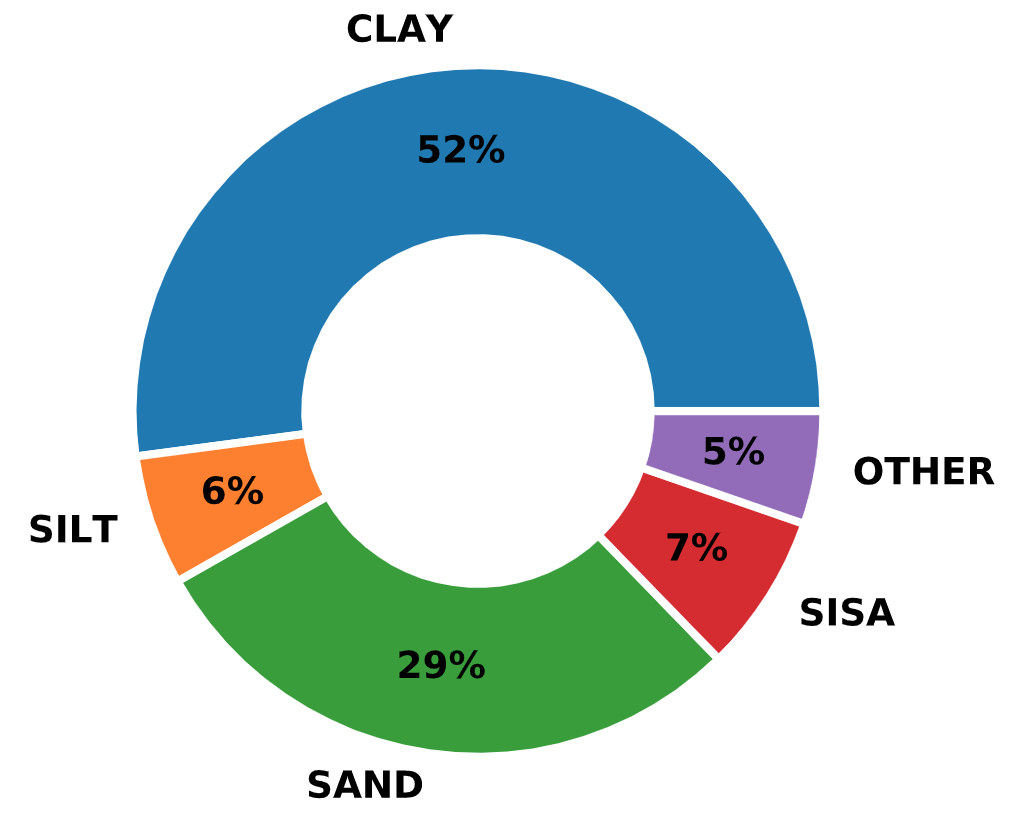
Fig. 2.4 Distribution of Soil Types in the Olson APC Database¶
2.2.1.3. Data Format and ETL¶
The Olson APC Database is referred to as a “database” but it was in neither hierarchical nor relational format and it could not be queried in a standard way. Instead, all information was contained within a single text file and a collection of pdf files with load test curves. Listing 2.1 presents the details of two records from the database, LTN 11 and LTN 13. Data for every record is organized in blocks with each block starting with the words “LTN Blank”. Starting from there, it was possible to break down each line and decode the values within.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | # ...
LTN Blank*
! The top 8' is cased off. N values are guessed from data elsewhere
! on the site. This is a 7 gage Monotube FN18 section.
* estimated N's
11 CIPC CIRC COMP 93.4 2.5 1.00 T 1195 3.4 None Morganza
18.00 0.00 4.71
18.00 25.00 4.71
8.00 93.40 2.11
-1.00 0.00 0.00
SACL 8 -5. 5 1 F T F F F T F F F
CLAY 8.0 0.67 0.113 39 78 52 0.01 0.00 0.00 0.00 0 0 0 0.00
CLAY 13.0 1.04 0.108 48 95 70 0.75 0.00 0.00 0.00 0 0 0 0.00
CLAY 6.5 1.51 0.122 29 38 15 0.76 0.00 0.00 0.00 0 0 0 0.00
SASI 4.0 1.83 0.127 22 0 0 0.00 0.00 0.00 0.00 5 6 0 0.00
CLAY 7.0 2.14 0.113 41 82 55 0.70 0.00 0.00 0.00 0 0 0 0.00
CLAY 42.5 3.28 0.108 48 95 70 0.66 0.00 0.00 0.00 0 0 0 0.00
SAND 9.9 4.60 0.133 19 0 0 0.00 0.00 0.00 0.00 60 72 0 0.00
SAND 10.0 4.95 0.133 19 0 0 0.00 0.00 0.00 0.00 70 84 0 0.00
0 340 340 0 0.83 0.30 4 37 3
# ...
LTN Blank*
! The top 8' is cased off. N values are guessed from data elsewhere
! on the site.
* estimated N's
13 STLP CIRC COMP 86.6 2.6 1.00 F 1700 10.6 None Morganza
18.00 4.71
SACL 6 -5. 5 1 F T F F F T F F F
CLAY 8.0 0.28 0.000 39 78 52 0.01 0.00 0.00 0.00 -1 -1 0 0.00
CLAY 19.5 1.24 0.000 39 78 52 0.75 0.00 0.00 0.00 0 0 0 0.00
SASI 4.0 1.84 0.000 22 0 0 0.00 0.00 0.00 0.00 5 6 0 0.00
CLAY 49.5 3.10 0.000 47 92 62 0.66 0.00 0.00 0.00 0 0 0 0.00
SAND 3.0 4.33 0.000 19 0 0 0.00 0.00 0.00 0.00 57 68 0 0.00
SAND 10.0 4.44 0.000 19 0 0 0.00 0.00 0.00 0.00 75 90 0 0.00
0 510 540 0 0.64 0.60 4 46 3
# ...
|
Focusing on LTN 11, Listing 2.2 expands the lines and adds variable names (in parentheses) for each value. These lines are highlighted in blue color. Table 8 (in the appendix) offers details on the variables defined in the raw data file of the Olson APC Database. Variables are described in the order presented in Listing 2.2. It is clear that information was stored in a systematic manner with varying data lines for varying number of layers in the associated soil profiles. In fact, the Olson APC Database was not a standard “database” but rather a FORTRAN program that could carry out filtering and analytical operations. FORTRAN was identified as the best option at the time although Dr. Olson in his notes does mention that porting the data to a relational database would be beneficial.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | LTN Blank*
(Comment)
! The top 8' is cased off. N values are guessed from data elsewhere
! on the site. This is a 7 gage Monotube FN18 section.
(Warning)
* estimated N's
(LTN) (Type) (Shape) (Load) (Len) (ExpL) (DR) (Tapr) (AEOL) (Wgt) (Site) (Loc)
11 CIPC CIRC COMP 93.4 2.5 1.00 T 1195 3.4 None Morganza
(PD) (LD) (CIR)
18.00 0.00 4.71
18.00 25.00 4.71
8.00 93.40 2.11
-1.00 0.00 0.00
(PROF) (NL) (EWT) (SQF) (IC) (Vib) (REO) (TS) (UTB) (UTS) (Case) (PDr) (RDr) (Jet)
SACL 8 -5. 5 1 F T F F F T F F F
(Soil) (HL) (EVSO) (TUW) (WC) (LL) (PI) (UU) (FV) (MS) (QT) (N) (Nc) (QC) (FSL)
CLAY 8.0 0.67 0.113 39 78 52 0.01 0.00 0.00 0.00 0 0 0 0.00
CLAY 13.0 1.04 0.108 48 95 70 0.75 0.00 0.00 0.00 0 0 0 0.00
CLAY 6.5 1.51 0.122 29 38 15 0.76 0.00 0.00 0.00 0 0 0 0.00
SASI 4.0 1.83 0.127 22 0 0 0.00 0.00 0.00 0.00 5 6 0 0.00
CLAY 7.0 2.14 0.113 41 82 55 0.70 0.00 0.00 0.00 0 0 0 0.00
CLAY 42.5 3.28 0.108 48 95 70 0.66 0.00 0.00 0.00 0 0 0 0.00
SAND 9.9 4.60 0.133 19 0 0 0.00 0.00 0.00 0.00 60 72 0 0.00
SAND 10.0 4.95 0.133 19 0 0 0.00 0.00 0.00 0.00 70 84 0 0.00
(QCT) (QMTD) (QMP) (QBF) (SFD) (SFP) (DQF) (SetUpTm) (Ref)
0 340 340 0 0.83 0.30 4 37 3
|
Part of the original FORTRAN code of the Olson APC Database was made available to the author but it was lacking documentation and was impossible to compile, possibly due to missing script files. It would have been great to get Dr. Olson’s code to work again but given the overarching goal of modernizing data processing and analysis of pile load tests, a Python algorithm was developed to extract all data from the APC data file. This algorithm is presented in Listing 2.3.
import re
from app import db
from .aux import data_owner
from app.models import Locations, Projects, Misc, Borings, Layers, \
Piles, LoadTests, StaticTests, InterpCapacities
def extract_olson_records(fname):
""" Extracts all records from the Olson Raw file as a list of strings
"""
records = []
with open(fname, 'r') as f:
for record in re.findall(r'LTN Blank(.*?)\n\s+\n', f.read(), re.S):
# the split removes the first line
records.append(record.split('\n', 1)[1])
return records
def extract_olson_values(record):
""" Given a raw record, this function will extract all record values.
Returns a dictionary.
"""
val_dict = {}
description = ''
warning = ''
line_count = 0
# Extract description and warning, if any
for line in record.splitlines():
if line[0] == '!':
description += line[2:]
description = re.sub(' +', ' ', description)
line_count += 1
elif line[0] == '*':
warning += line[2:]
warning = re.sub(' +', ' ', warning)
line_count += 1
val_dict['description'] = description if description else None
val_dict['warning'] = warning if warning else None
# Extract first line of LTN data
ltn_line = record.splitlines()[:][line_count].split()
if len(ltn_line) > 12:
loc = []
while len(ltn_line) > 11:
loc.append(ltn_line.pop(-1))
ltn_line += [' '.join(loc[::-1])]
val_dict['source_id'] = int(ltn_line[0])
val_dict['type'] = ltn_line[1]
val_dict['shape'] = ltn_line[2]
val_dict['direction'] = ltn_line[3]
val_dict['length'] = float(ltn_line[4])
val_dict['emb_length'] = float(ltn_line[4]) - float(ltn_line[5])
val_dict['dratio'] = float(ltn_line[6])
val_dict['tapered'] = True if ltn_line[7] == 'T' else False
val_dict['aeol'] = int(ltn_line[8])
val_dict['weight'] = float(ltn_line[9])
val_dict['site_name'] = eval(ltn_line[10])
val_dict['location'] = ltn_line[11]
line_count += 1
# Extract (tapered) dimensions
first_dim_line = record.splitlines()[:][line_count].split()
# if len(first_dim_line) == 2:
if not val_dict['tapered']:
val_dict['diameter'] = float(first_dim_line[0])
val_dict['circumference'] = float(first_dim_line[1])
if len(first_dim_line) == 3:
val_dict['square_circ'] = float(first_dim_line[2])
else:
val_dict['square_circ'] = None
val_dict['taper_dims'] = None
line_count += 1
else:
val_dict['square_circ'] = None
taper_dict = {'diameter': [], 'length': [], 'circumference': []}
val_dict['diameter'] = float(first_dim_line[0])
val_dict['circumference'] = float(first_dim_line[2])
for line in record.splitlines()[:][line_count:]:
if line.split()[0] != '-1.00':
taper_dict['diameter'].append(float(line.split()[0]))
taper_dict['length'].append(float(line.split()[1]))
taper_dict['circumference'].append(float(line.split()[2]))
line_count += 1
else:
line_count += 1
break
val_dict['taper_dims'] = taper_dict
# Extract mid line data
mid_line = record.splitlines()[:][line_count].split()
val_dict['predom_soil'] = mid_line[0]
val_dict['layer_count'] = int(mid_line[1])
val_dict['ewt'] = float(mid_line[2])
val_dict['sqf'] = int(mid_line[3])
val_dict['i_code'] = float(mid_line[4])
val_dict['vibro'] = True if mid_line[5] == 'T' else False
val_dict['reo_check'] = True if mid_line[6] == 'T' else False
val_dict['ts_check'] = True if mid_line[7] == 'T' else False
val_dict['ut_boring'] = True if mid_line[8] == 'T' else False
val_dict['ut_sounding'] = True if mid_line[9] == 'T' else False
val_dict['cased'] = True if mid_line[10] == 'T' else False
val_dict['predrilled'] = True if mid_line[11] == 'T' else False
val_dict['relief_drilled'] = True if mid_line[12] == 'T' else False
val_dict['jetted'] = True if mid_line[13] == 'T' else False
line_count += 1
# Extract layer data
layer_dict = {
'index': [], 'soil_type': [], 'height': [], 'evso': [], 'tuw': [],
'water_content': [], 'liquid_limit': [], 'plasticity': [], 'ssuu': [],
'ssfv': [], 'ssms': [], 'ssqt': [], 'nval': [], 'cnval': [], 'qc': [],
'fsl': []}
li = 0
for line in record.splitlines()[:][line_count:-1]:
li += 1
ll = [i if i not in ['0', '0.00', '0.000']
else None for i in line.split()]
layer_dict['index'].append(li)
layer_dict['soil_type'].append(ll[0])
layer_dict['height'].append(float(ll[1]))
layer_dict['evso'].append(float(ll[2]) if ll[2] else None)
layer_dict['tuw'].append(float(ll[3]) * 1000 if ll[3] else None)
layer_dict['water_content'].append(int(ll[4]) if ll[4] else None)
layer_dict['liquid_limit'].append(int(ll[5]) if ll[5] else None)
layer_dict['plasticity'].append(int(ll[6]) if ll[6] else None)
layer_dict['ssuu'].append(float(ll[7]) if ll[7] else None)
layer_dict['ssfv'].append(float(ll[8]) if ll[8] else None)
layer_dict['ssms'].append(float(ll[9]) if ll[9] else None)
layer_dict['ssqt'].append(float(ll[10]) if ll[10] else None)
layer_dict['nval'].append(int(ll[11]) if ll[11] else None)
layer_dict['cnval'].append(int(ll[12]) if ll[12] else None)
layer_dict['qc'].append(int(ll[13]) if ll[13] else None)
layer_dict['fsl'].append(float(ll[14]) if ll[14] else None)
line_count += 1
val_dict['layers'] = layer_dict
# Extract final line od data
end_line = record.splitlines()[:][line_count].split()
val_dict['half_inch_capacity'] = int(end_line[0]) \
if end_line[0] != '0' else None
val_dict['davisson_capacity'] = int(end_line[1]) \
if end_line[1] != '0' else None
val_dict['max_load'] = int(end_line[2]) \
if end_line[2] != '0' else None
val_dict['brown_capacity'] = int(end_line[3]) \
if end_line[3] != '0' else None
val_dict['davisson_displacement'] = float(end_line[4]) \
if end_line[4] != '0.00' else None
val_dict['max_displacement'] = float(end_line[5]) \
if end_line[5] != '0.00' else None
val_dict['dqf'] = int(end_line[6])
val_dict['setup_time'] = int(end_line[7])
val_dict['source_ref'] = int(end_line[8])
return val_dict
def add_olson_data(record, qs=None):
""" Accepts an Olson record as extracted from ``extract_olson_values()``
and commits this record to the database.
"""
loc = Locations(
description=record['location'])
db.session.add(loc)
prj = Projects(
user_id=data_owner().id,
source_db='Olson APC',
source_id=record['source_id'],
description=record['description'],
warning=record['warning'],
source_ref=record['source_ref'],
dqf=record['dqf'],
location=loc)
db.session.add(prj)
misc = Misc(
reo_check=record['reo_check'],
ts_check=record['ts_check'],
ut_boring=record['ut_boring'],
ut_sounding=record['ut_sounding'],
i_code=record['i_code'],
project=prj)
db.session.add(misc)
boring = Borings(
predom_soil=record['predom_soil'],
layer_count=record['layer_count'],
ewt=record['ewt'],
sqf=record['sqf'],
project=prj
)
db.session.add(boring)
cnt = len(record['layers']['index'])
for i in range(cnt):
layer = Layers(
index=record['layers']['index'][i],
soil_type=record['layers']['soil_type'][i],
height=record['layers']['height'][i],
evso=record['layers']['evso'][i],
tuw=record['layers']['tuw'][i],
water_content=record['layers']['water_content'][i],
nval=record['layers']['nval'][i],
cnval=record['layers']['cnval'][i],
ssuu=record['layers']['ssuu'][i],
ssfv=record['layers']['ssfv'][i],
ssms=record['layers']['ssms'][i],
ssqt=record['layers']['ssqt'][i],
qc=record['layers']['qc'][i],
fsl=record['layers']['fsl'][i],
liquid_limit=record['layers']['liquid_limit'][i],
plasticity=record['layers']['plasticity'][i],
boring=boring)
db.session.add(layer)
pile = Piles(
type=record['type'],
shape=record['shape'],
length=record['length'],
emb_length=record['emb_length'],
diameter=record['diameter'],
circumference=record['circumference'],
square_circ=record['square_circ'],
aeol=record['aeol'],
weight=record['weight'] * 1000,
dratio=record['dratio'],
tapered=record['tapered'],
vibro=record['vibro'],
cased=record['cased'],
predrilled=record['predrilled'],
relief_drilled=record['relief_drilled'],
jetted=record['jetted'],
project=prj
)
db.session.add(pile)
load_test = LoadTests(
direction='Compression (Static)' if record['direction'] == 'COMP'
else 'Tension (Static)',
setup_time=record['setup_time'],
pile=pile
)
db.session.add(load_test)
if qs:
i_slt = 1
for i in qs:
static_test = StaticTests(
index=i_slt,
load=i[0],
displacement=i[1],
load_test=load_test
)
db.session.add(static_test)
i_slt += 1
if record['half_inch_capacity']:
ic = InterpCapacities(
load=record['half_inch_capacity'],
displacement=0.5,
type='Load @ 0.5 inches',
origin='source DB',
load_test=load_test
)
db.session.add(ic)
if record['davisson_capacity']:
ic = InterpCapacities(
load=record['davisson_capacity'],
displacement=record['davisson_displacement'],
type='Standard Davisson',
origin='source DB',
load_test=load_test
)
db.session.add(ic)
if record['brown_capacity']:
ic = InterpCapacities(
load=record['brown_capacity'],
type='Brown',
origin='source DB',
load_test=load_test
)
db.session.add(ic)
if record['max_load']:
ic = InterpCapacities(
load=record['max_load'],
type='Maximum Load',
origin='source DB',
load_test=load_test
)
db.session.add(ic)
if record['max_displacement']:
ic = InterpCapacities(
displacement=record['max_displacement'],
type='Maximum Displacement',
origin='source DB',
load_test=load_test
)
db.session.add(ic)
db.session.commit()
The output of the data extraction algorithm is a Python dictionary which was then used to port all data to the relational database presented in the next section.
The Olson APC Database consisted of a large data file (Listing 2.1) containing project data. A few load test interpretations were stored, i.e. Davisson capacity (QMDT), peak load (QMP), capacity at 0.5-inch pile head settlement (QCT, aka. CalTrans Capacity), etc. However, load test data points were not stored in the data file. Instead, original load test curves in .pdf format from the source projects were used (see Fig. 2.5 for LTN 13). Dr. Olson provided figures for 487 records out of the total 939. It was crucial to include the load test data points in the NYU Pile Load Test Data Warehouse, therefore, all figures were digitized using the tool WebPlotDigitizer.
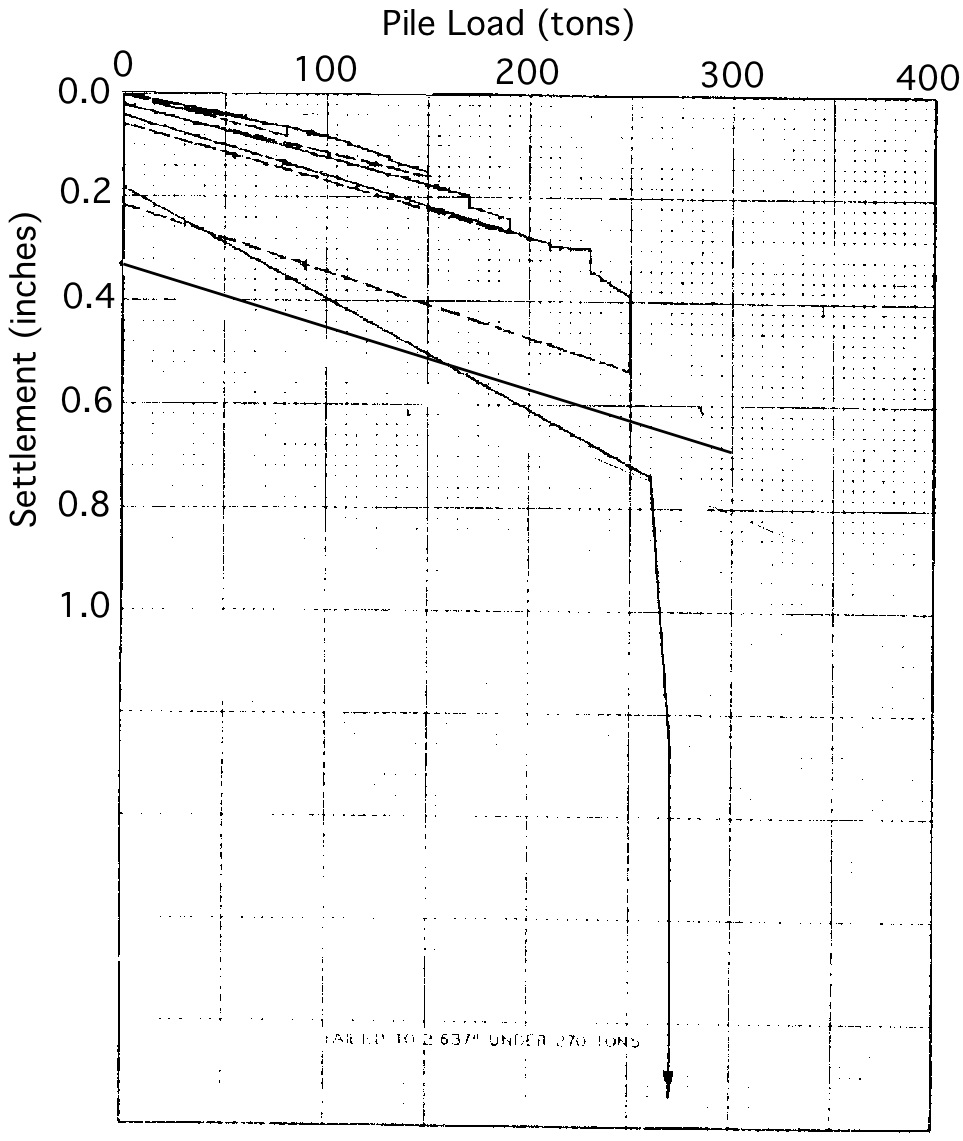
Fig. 2.5 Load/Settlement plot for Olson APC Database LTN 13¶
2.2.2. Iowa PILOT Database¶
2.2.2.1. Background¶
The Pile-Load Tests (PILOT) database is the result of a funded research project by the Iowa Department of Transportation carried out at the Institute for Transportation of the Iowa State University (Roling et al., 2010, 2011). While most publicly available load test databases suffer from poor data quality, records in the PILOT database were first analyzed for reliability and then used for the establishment of LRFD resistance factors for design and construction control of driven pile foundations in Iowa. PILOT is an amalgamated, electronic source of information consisting of both static and dynamic data for pile load tests conducted in the State of Iowa and includes historical data on pile load tests dating from 1966 to 1989. It is therefore considered a reliable source of data for future studies.
Additional information on this research project is available at http://srg.cce.iastate.edu/lrfd/.
Currently providing an electronically organized assimilation of geotechnical and pile load test data for 274 piles of various types (e.g., steel H-shaped, timber, pipe, Monotube, and concrete), PILOT (http://srg.cce.iastate.edu/lrfd/) is on par with such familiar national databases used in the calibration of LRFD resistance factors for pile foundations as the FHWA’s Deep Foundation Load Test Database. By narrowing geographical boundaries while maintaining a high number of pile load tests, PILOT exemplifies a model for effective regional LRFD calibration procedures.
2.2.2.2. Database Statistics¶
PILOT contains geotechnical and pile load test data for 274 piles of various types (i.e., steel H-shaped, timber, pipe, monotube, and concrete). The majority of the piles are steel H-piles (164 count) followed by timber (75 count) and steel pipe piles (16 count). Of particular importance are 10 steel H-piles that are accompanied by a plethora of information. Distribution of pile types is shown in Fig. 2.6.
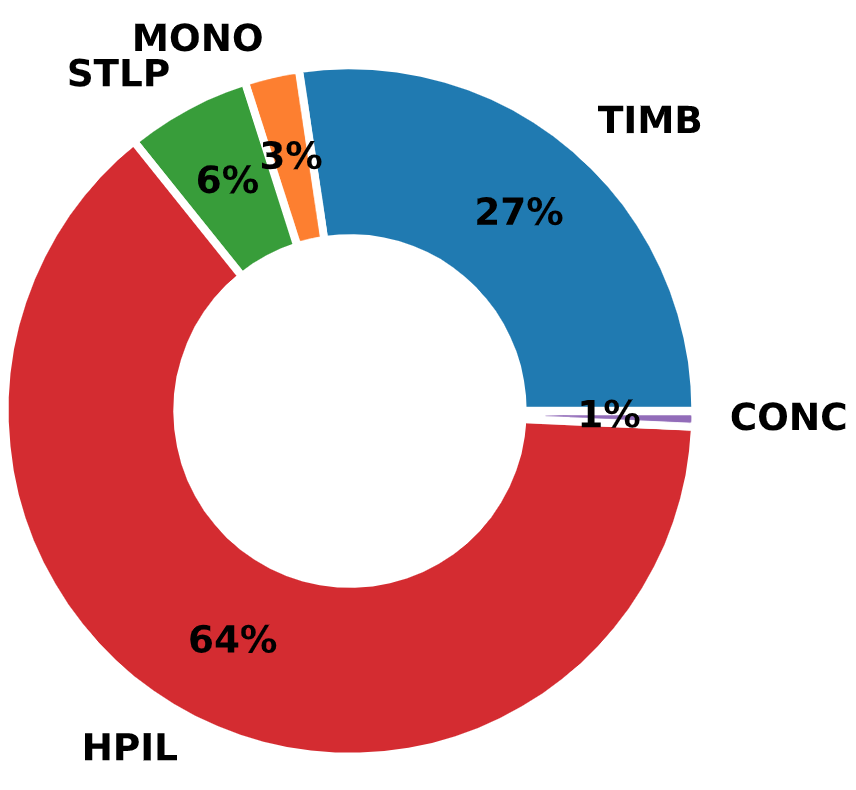
Fig. 2.6 Distribution of Pile Types in the Iowa PILOT Database¶
In addition to driving and statically load testing these piles to failure, most of the test piles were instrumented with strain gauges and dynamically monitored during driving and restrikes using the Pile Driving Analyzer (PDA) device. Moreover, the subsurface conditions at the location of each of the test piles were characterized using various laboratory tests (i.e., moisture content, grain-size distribution, Atterberg limits, consolidation, and Triaxial Consolidated-Undrained compression tests) and in-situ tests (e.g., Standard Penetration Test (SPT), Cone Penetration Test (CPT), and Borehole Shear Test (BST)). In a few cases, ground instrumentation (i.e., push-in pressure cells) was used to capture horizontal stress and porewater pressure data near the test pile during driving and static load testing.
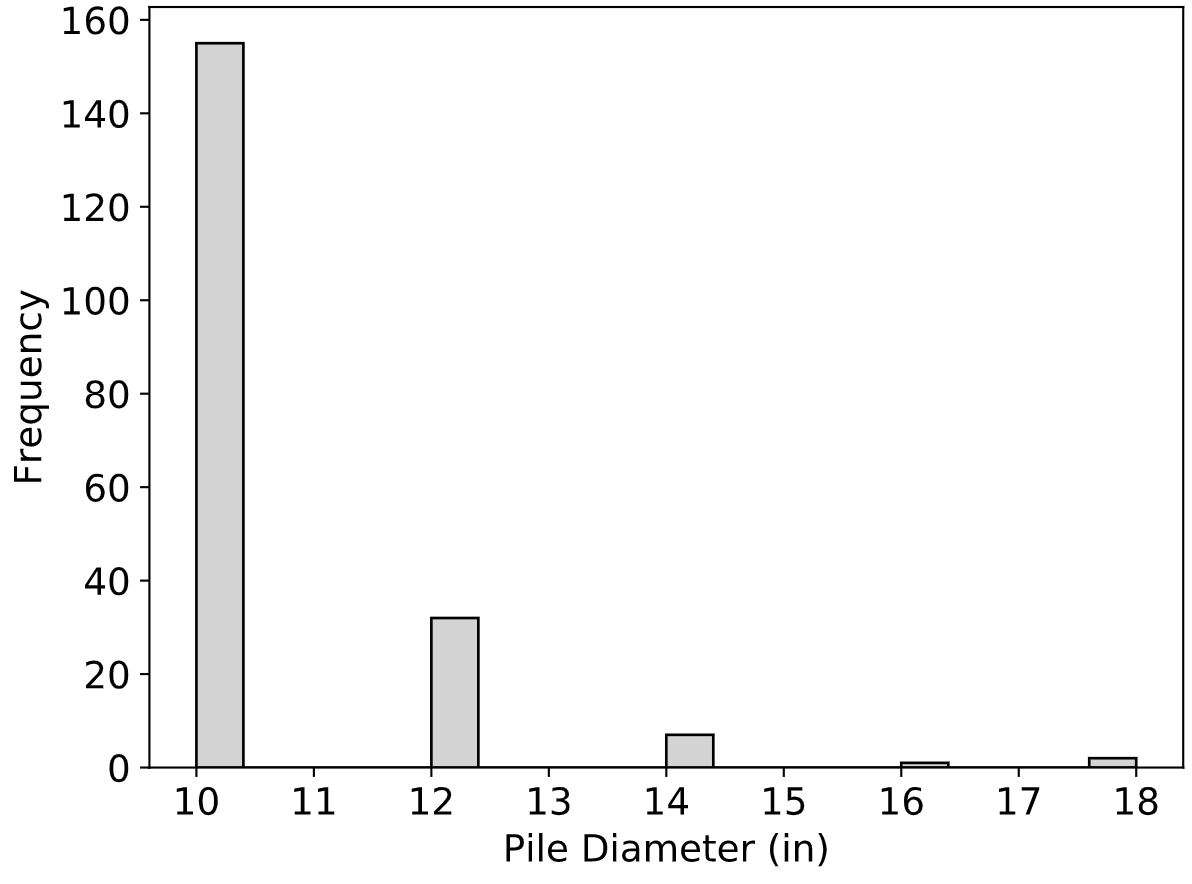
Fig. 2.7 Distribution of Pile Diameters in the Iowa PILOT Database¶
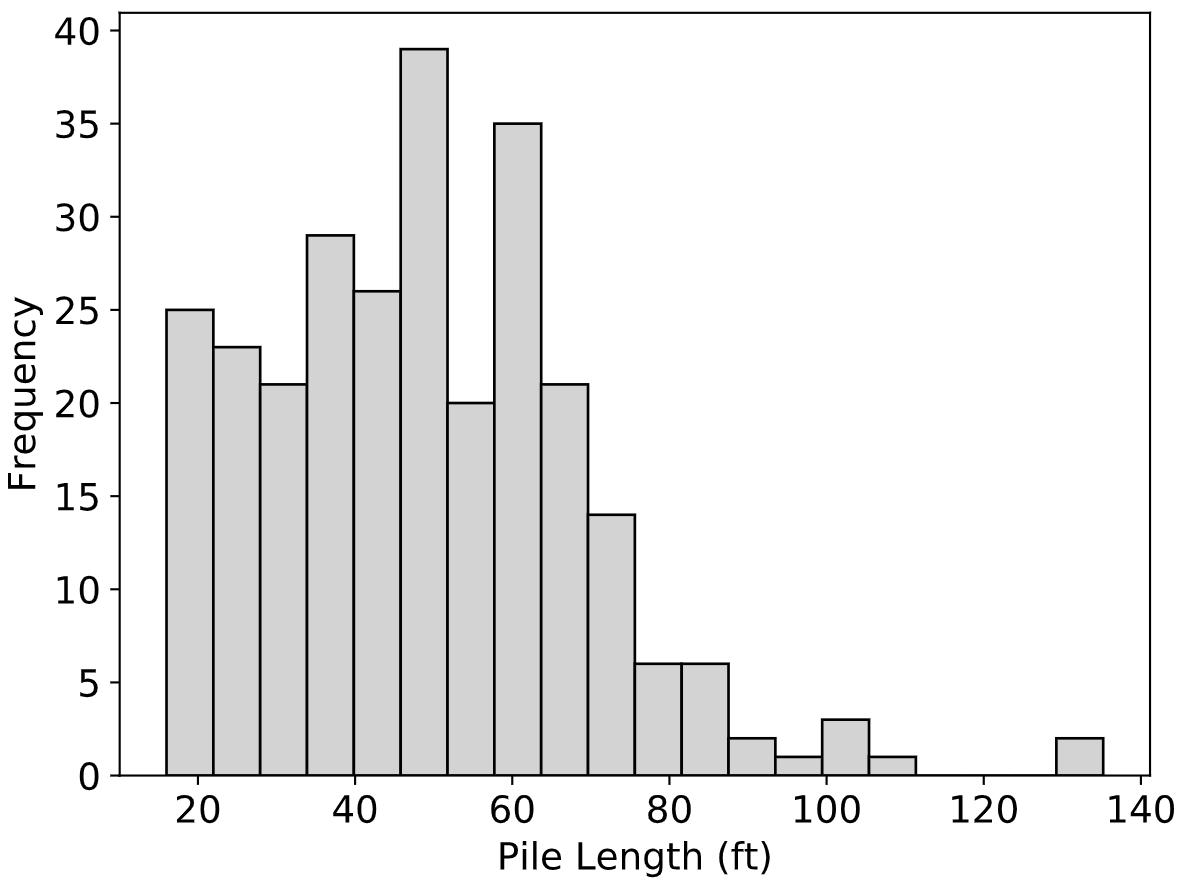
Fig. 2.8 Distribution of Pile Lengths in the Iowa PILOT Database¶
In contrast to the Olson APC Database, the distribution of soil types that the piles in PILOT were driven into is equally spread between sandy, clayey and mixed. This can be seen in Fig. 2.9.
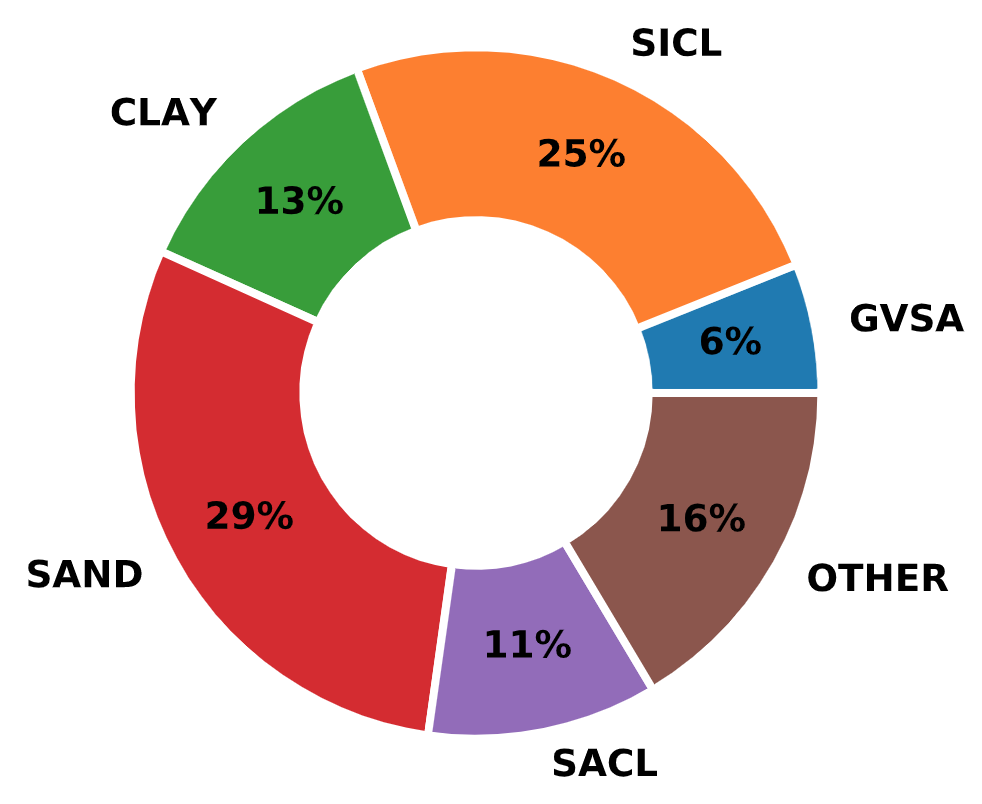
Fig. 2.9 Distribution of Soil Types in the Iowa PILOT Database¶
2.2.2.3. Data Format and ETL¶
PILOT was designed in and distributed as a Microsoft Access database. It was designed to perform efficient filtering, sorting, and querying procedures on the amassed dataset. The developers of PILOT did a great job in delivering a user-friendly environment, however, the inherit limitations of Microsoft Access are hard to overcome.
Information in the PILOT database is organized in four tables, Pile Load Test Records (main table with 112 attributes, Table 9 in the appendix), Average Soil Profile (eight attributes, Table 10 in the appendix), Borehole/SPT Information (seven attributes, Table 11 in the appendix), and Static Load Test Results (four attributes, Table 12 in the appendix). There are three additional reference tables for Iowa counties, pile types and soil classification options.
The format of the PILOT database is relational but not normalized and with no apparent formal design implementation other than the logical clustering of related blocks of data. The E-R diagram of the database is presented in Fig. 2.10.
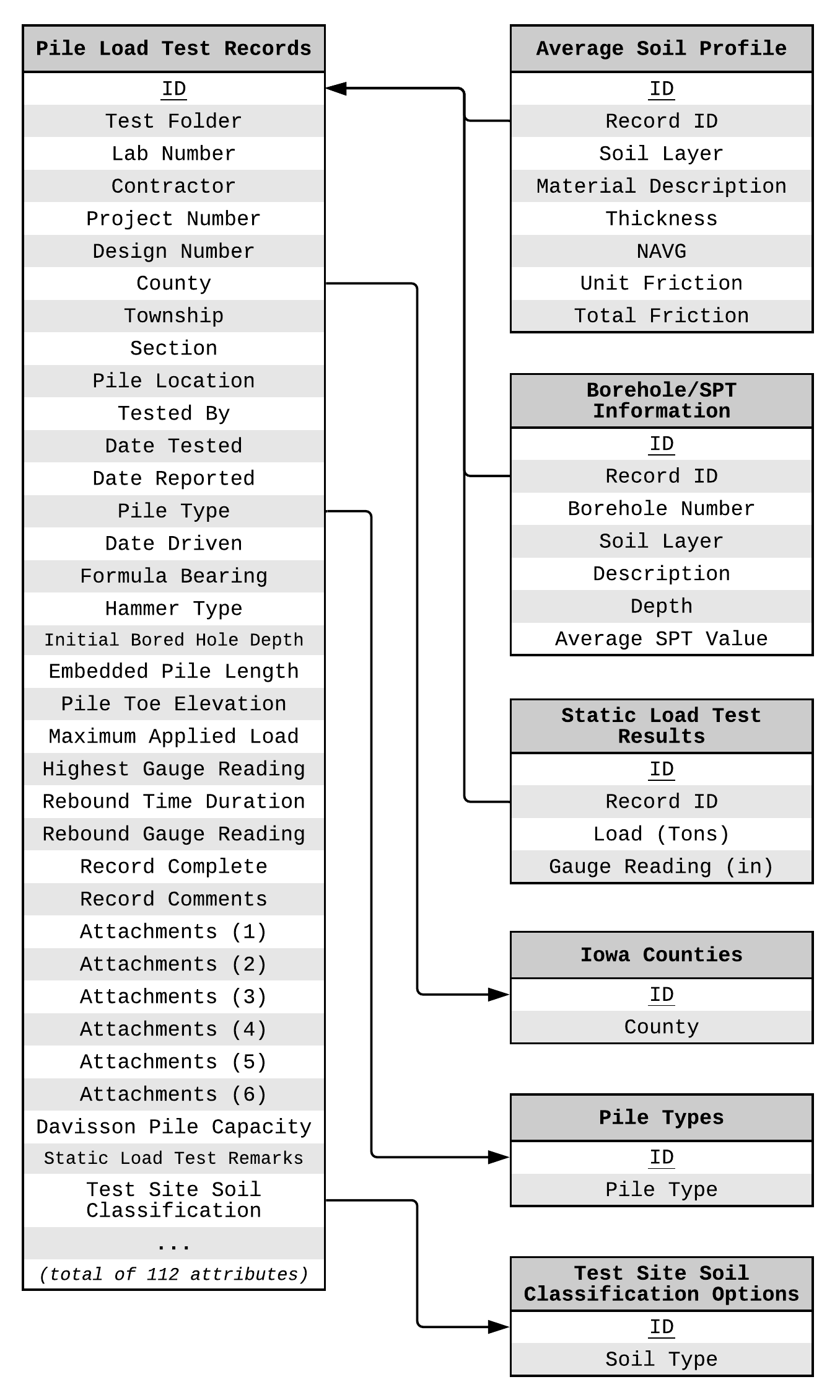
Fig. 2.10 E-R Diagram of the Iowa PILOT Database¶
While the quality of the data in the PILOT database is not questioned, noticeably absent were data on soil unit weight which hindered reliable effective stress and capacity calculations. Moreover, ground water table was recorded as an elevation without additional data on the elevation of the ground level in order to infer ground water table depth. Luckily, there was information on pile toe elevation for most records and combined with pile embedded depth, it was possible to infer water table depth for some records. Lastly, data for Cone Penetration Tests (CPT) and Borehole Shear Tests (BST) were referenced via relative links to local files but were not included.
All data from the PILOT database was ported to the NYU database. There were two options to accomplish this task. The first was to use standard Microsoft tools that could transfer the MS Access database to a temporary database on MS SQL Server maintaining all metadata from the MS Access database. Then, the temporary database on MS SQL Server could be queried and the data transferred to NYU Pile Capacity.
The second option was to export all tables from MS Access as .csv files and produce a Python program to process these files. This was the option implemented due to the fact that it did not require temporary infrastructure (setting up a temporary MS SQL server) and the ETL process could then be more streamlined and reproducible.
Table 9, Table 10, Table 11 and Table 12 in the appendix detail how the original PILOT database attributes were mapped to the NYU Pile Capacity attributes. And Listing 2.4 presents the program that was written to extract, transform and load the data from Iowa PILOT to NYU Pile Capacity based on these mappings.
# -- Imports ---------------------------------------------------------------- #
import os
import pandas as pd
from app import db
from .aux import data_owner
from app.models import Locations, Projects, Piles, Borings, Layers, LoadTests, \
StaticTests, InterpCapacities, CalcCapacities, Attachments, Misc
from tqdm import tqdm
# -- File Paths ------------------------------------------------------------- #
IOWA_DATA_DIR = os.path.join('app', 'etl', '_data_sources', 'iowa')
plt_records_path = os.path.join(IOWA_DATA_DIR, 'Pile Load Test Records.txt')
counties_path = os.path.join(IOWA_DATA_DIR, 'Iowa Counties.txt')
pile_types_path = os.path.join(IOWA_DATA_DIR, 'Pile Types.txt')
avg_soil_path = os.path.join(IOWA_DATA_DIR, 'Average Soil Profile.txt')
slt_path = os.path.join(IOWA_DATA_DIR, 'Static Load Test Results.txt')
# -- Main Import Function --------------------------------------------------- #
def load_iowa_records():
""" Iterates through source files and adds the Iowa PILOT records to the
database
"""
plt_records = pd.read_csv(plt_records_path)
counties = pd.read_csv(counties_path)
pile_types = pd.read_csv(pile_types_path)
avg_soil = pd.read_csv(avg_soil_path)
slt_results = pd.read_csv(slt_path)
print('--- Importing Iowa PILOT records ---')
for i in tqdm(range(len(plt_records))):
# -- Adding Location Data ------------------------------------------- #
loc = Locations(
county=counties.loc[
counties['ID'] == plt_records['County'][i], 'County'].iloc[0],
township=plt_records['Township'][i],
description=plt_records['Pile Location'][i])
db.session.add(loc)
# -- Adding Project Data -------------------------------------------- #
wt_loc = plt_records['Water Table Location'][i]
if pd.isna(wt_loc):
desc = None
else:
desc = 'Water Table ' + str(wt_loc)
prj = Projects(
user_id=data_owner().id,
source_db='Iowa PILOT',
source_id=int(plt_records['ID'][i]),
contractor=plt_records['Contractor'][i],
number=plt_records['Project Number'][i],
description=desc,
location=loc)
db.session.add(prj)
# -- Adding Pile Data ----------------------------------------------- #
emb_pile_length = plt_records['Embedded Pile Length'][i]
pile_length = plt_records['Pile Length'][i]
if pd.isna(pile_length):
pile_length = pile_types.loc[
pile_types['ID'] == plt_records['Pile Type'][i], 'Length'
].iloc[0]
if pd.isna(pile_length):
pile_length = emb_pile_length
pile = Piles(
project=prj,
type=pile_types.loc[
pile_types['ID'] == plt_records['Pile Type'][i], 'Type'
].iloc[0],
shape=pile_types.loc[
pile_types['ID'] == plt_records['Pile Type'][i], 'Shape'
].iloc[0] if not pd.isna(pile_types.loc[
pile_types['ID'] == plt_records['Pile Type'][i], 'Shape'
].iloc[0]) else None,
emb_length=emb_pile_length,
length=pile_length,
diameter=pile_types.loc[
pile_types['ID'] == plt_records['Pile Type'][i], 'Diameter'
].iloc[0] if not pd.isna(pile_types.loc[
pile_types['ID'] == plt_records['Pile Type'][i], 'Diameter'
].iloc[0]) else None,
cross_area=plt_records['Pile Cross-Sectional Area'][i] if not
pd.isna(plt_records['Pile Cross-Sectional Area'][i]) else None,
weight=plt_records['Weight of Pile'][i] if not pd.isna(
plt_records['Weight of Pile'][i]) else None,
predrill_depth=plt_records['Initial Bored Hole Depth'][i] if
plt_records['Initial Bored Hole Depth'][i] != 0 else None,
predrilled=True if plt_records['Initial Bored Hole Depth'][i] != 0
else None,
date_driven=pd.to_datetime(
plt_records['Date Driven'][i] if not
pd.isna(plt_records['Date Driven'][i]) else None),
design_load=plt_records['Design Load'][i] if not
pd.isna(plt_records['Design Load'][i]) else None,
toe_elevation=plt_records['Pile Toe Elevation'][i] if not
pd.isna(plt_records['Pile Toe Elevation'][i]) else None,
)
db.session.add(pile)
# -- Adding Soil Data ----------------------------------------------- #
soil_class = {1: 'CLAY', 2: 'SAND', 3: 'SACL'}
p_soil = plt_records['Test Site Soil Classification'][i]
boring = Borings(
project=prj,
name='Average Soil Profile',
predom_soil=soil_class[p_soil] if not pd.isna(p_soil) else None,
remarks=plt_records['Borehole Numbers at Test Pile Location'][i],
)
db.session.add(boring)
layers = avg_soil[avg_soil['Record ID'] == i+1]
for l in layers.index:
layer = Layers(
boring=boring,
index=layers['Soil Layer'][l] if not
pd.isna(layers['Soil Layer'][l]) else None,
soil_type=iowa_soil_dict[layers['Material Description'][l]] if
not pd.isna(layers['Material Description'][l]) else None,
description=layers['Material Description'][l],
height=layers['Thickness'][l],
nval=layers['NAVG'][l]
if not pd.isna(layers['NAVG'][l]) else None,
iowa_unit_friction=layers['Unit Friction'][l],
iowa_total_friction=layers['Total Friction'][l],
)
db.session.add(layer)
# -- Adding load test data ------------------------------------------ #
load_test = LoadTests(
pile=pile,
direction='Compression (Static)',
tested_by=plt_records['Tested By'][i],
date_tested=pd.to_datetime(
plt_records['Date Tested'][i] if not
pd.isna(plt_records['Date Tested'][i]) else None),
rebound_time=plt_records['Rebound Time Duration'][i] if not
pd.isna(plt_records['Rebound Time Duration'][i]) else None,
rebound_displacement=plt_records['Rebound Gauge Reading'][i],
remarks=plt_records['Static Load Test Remarks'][i],
reliable=True
if plt_records['Load Test Reliability Classification'][i] == 1
else False,
)
db.session.add(load_test)
static_test = slt_results[slt_results['Record ID'] == i+1]
i_slt = 1
for p in static_test.index:
slt_point = StaticTests(
index=i_slt,
load=static_test['Load (Tons)'][p] * 1000,
displacement=static_test['Gauge Reading (in)'][p],
load_test=load_test
)
db.session.add(slt_point)
i_slt += 1
# -- Adding Interpreted Capacity Data ------------------------------- #
interp_dict = {
'Maximum Applied Load': 'Maximum Load',
'Highest Gauge Reading': 'Maximum Displacement',
'Davisson Pile Capacity': 'Standard Davisson'
}
for key in interp_dict:
ival = plt_records[key][i]
if not pd.isna(ival) and float(ival) > 0:
ic = InterpCapacities(
load=float(ival) * 2 if key != 'Highest Gauge Reading'
else None,
displacement=float(ival) if key == 'Highest Gauge Reading'
else None,
type=interp_dict[key],
origin='source DB',
load_test=load_test)
db.session.add(ic)
# -- Adding Calculated Capacity Data -------------------------------- #
calc_dict = {
'Formula Bearing': 'Iowa DOT Modified ENR (bearing)',
'Theoretical End Bearing': 'Iowa Theoretical End Bearing',
'Theoretical Pile Capacity': 'Iowa Theoretical Capacity',
'Blue Book Capacity': 'Iowa Blue Book Method',
'SPT Capacity': 'Meyerhof',
'Alpha Capacity': 'API 1984',
'Beta Capacity': 'Beta Burland 1973',
'Nordland Capacity': 'Nordlund',
'ENR Capacity': 'ENR Formula',
'Modified ENR Capacity': 'Iowa DOT Modified ENR',
'Gates Capacity': 'Gates Formula',
'FHWA Modified Gates Capacity': 'FHWA Modified Gates Formula',
'Janbu Capacity': 'Janbu Formula',
'PCUBC Capacity': 'Pacific Coast Uniform BC Formula',
'WSDOT Capacity': 'Washington DOT Formula'
}
for key in calc_dict:
cval = plt_records[key][i]
if not pd.isna(cval) and float(cval) > 0:
cc = CalcCapacities(
load=float(cval) * 2,
type=calc_dict[key],
origin='source DB',
pile=pile)
db.session.add(cc)
# -- Adding Attachments --------------------------------------------- #
attach_attr = ['Attachments (1)', 'Attachments (2)', 'Attachments (3)',
'Attachments (4)', 'Attachments (5)', 'Attachments (6)']
for attr in attach_attr:
val = plt_records[attr][i]
if not pd.isna(val):
fname = val.split('#')[0]
furl = val.split('#')[1]
attachment = Attachments(
project=prj,
file_name=fname,
file_url=furl
)
db.session.add(attachment)
# -- Adding Miscellaneous Data -------------------------------------- #
misc = Misc(
project=prj,
iowa_test_folder=plt_records['Test Folder'][i],
iowa_lab_number=plt_records['Lab Number'][i],
iowa_design_number=plt_records['Design Number'][i],
iowa_section=plt_records['Section'][i],
iowa_date_reported=pd.to_datetime(
plt_records['Date Reported'][i] if not
pd.isna(plt_records['Date Reported'][i]) else None),
iowa_record_complete=plt_records['Record Complete'][i],
iowa_borehole_count=plt_records['Total Number of Boreholes'][i]
if not pd.isna(
plt_records['Total Number of Boreholes'][i]) else None,
iowa_spt_count=plt_records['Boreholes With SPT Data'][i] if not
pd.isna(plt_records['Boreholes With SPT Data'][i]) else None,
iowa_borehole_near_pile=plt_records[
'Borehole at Test Pile Location'][i]
)
db.session.add(misc)
db.session.commit()
2.2.3. FHWA DFLTD v.2¶
2.2.3.1. Background¶
The original version of DFLTD includes methods of search for foundations of specific site and pile characteristics from the more than 1,500 load test results available (Kalavar and Ealy, 2000). Although DFLTD claimed over 1,500 load tests, the author is not aware of any studies that have been able to employ a substantial portion of these tests in comparing interpreted and computing capacities because most tests lacked crucial information necessary for either interpreting the test, or computing the capacity. This is a problem with all piling databases. For example the Olson database classified tests into five data quality factors, for both soils information and pile load test information. Few tests in the entire Olson database achieved a top tier classification in both categories, and thus nearly all analyses were based on fewer than 100 high quality tests.
FHWA rekindled the effort to gather and distribute load test information on piles, as part of its effort to develop a method for predicting the axial capacity of large diameter open ended pipe piles. This effort resulted in the release of the Deep Foundation Load Test Database v.2 (DFLTD v.2) in February 2017 (Petek et al., 2016). This updated version of the DFLTD v.2 was developed as part of the Federal Highway Administration (FHWA) research project Bearing Resistance of Large Diameter Open-End Piles (2014–2017), and provides a collection of deep foundation load test data.
The release of DFLTD v.2 updated the query process, expanding upon the capabilities of the first version (Kalavar and Ealy, 2000). The graphical user interface within Microsoft Access allows load tests to be filtered based on a predefined set of options to view or export only those containing the desired project, foundation, and soil parameters. There is currently limited functionality to filter test records for data completion, to locate tests with all necessary parameters to carry out design calculations for the pile foundations included in the database. Furthermore, the process of extracting data, while sufficient for a case-by-case investigation, could not accommodate the need of this research endeavor to analyse cases in batch mode.
2.2.3.2. Database Statistics¶
Load test types in DFLTD v.2 include axial static, rapid (Statnamic), and dynamic load tests. Pile types include open and closed-end steel pipe piles, concrete cylinder piles, steel H-piles, pre-stressed concrete piles, drilled shafts, augercast piles, micropiles, timber piles, and others. As per the corresponding manual, pile load test data from the existing FHWA Deep Foundation Load Test Database (DFLTD, Version 1.0) was transferred to DFLTD v.2.
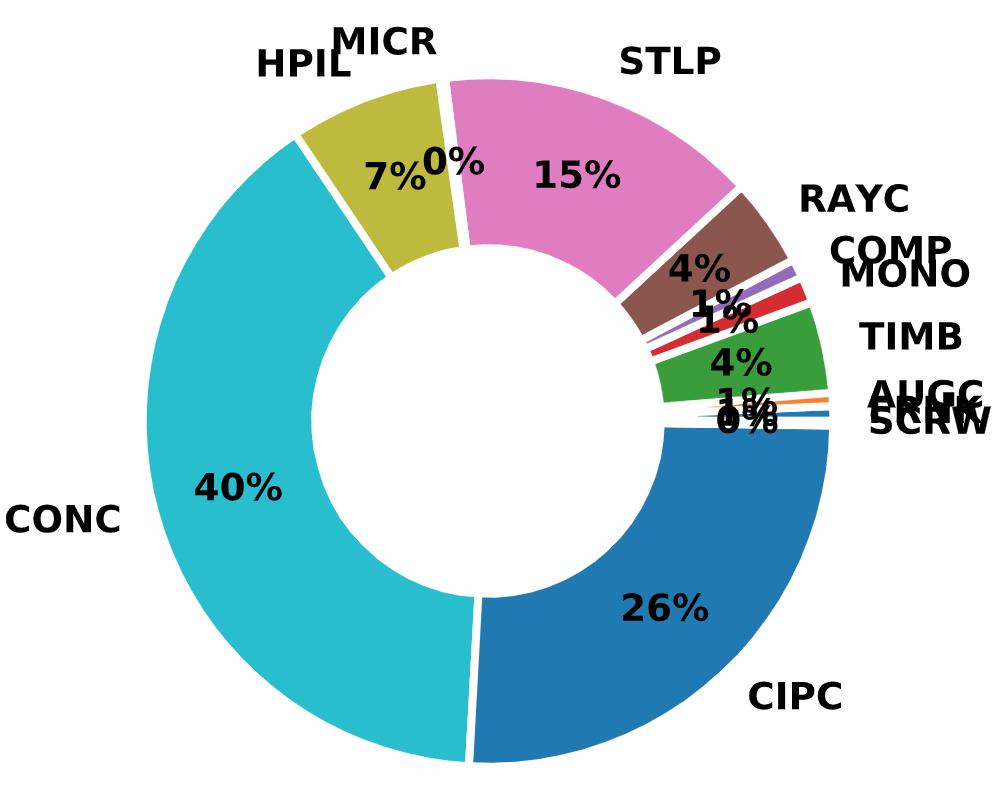
Fig. 2.11 Distribution of Pile Types in the FHWA DFLTD v.2¶
The records included in DFLTD v.2 were obtained from a large number of sources which included state highway departments, conference proceedings, journal articles, and engineering reports. The original data for these load tests was generally not available. Therefore, the LDOEP data including subsurface explorations, dynamic testing, and load test data (force, displacement, force distribution, and load transfer) was digitized from these publications.
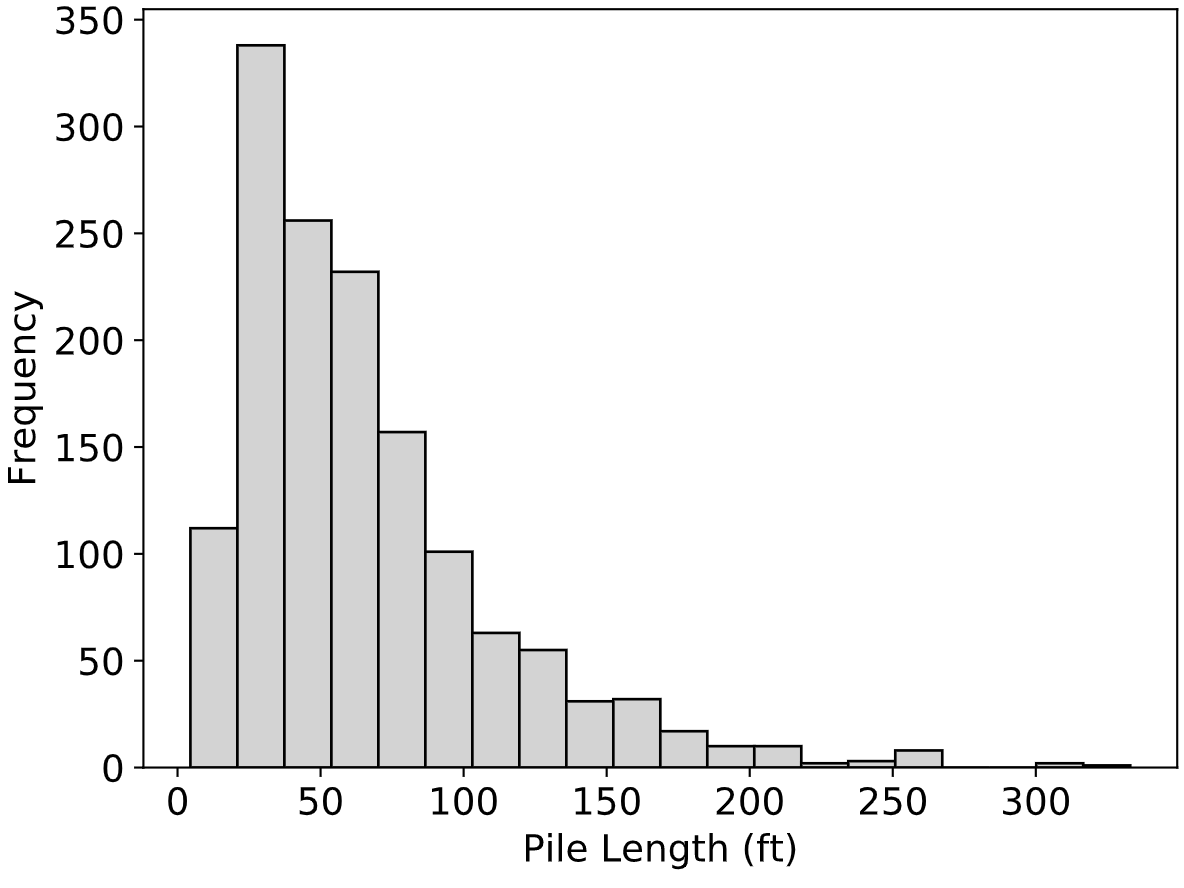
Fig. 2.12 Distribution of Pile Lengths in the FHWA DFLTD v.2¶
DFLTD v.2 used the following broad soil type classifications: cohesive, non-cohesive, intermediate geomaterial, rock, and variable (mixed). Soil types were classified as uniform if at least 70% of the soil along the pile side or base consisted of the specified material type.
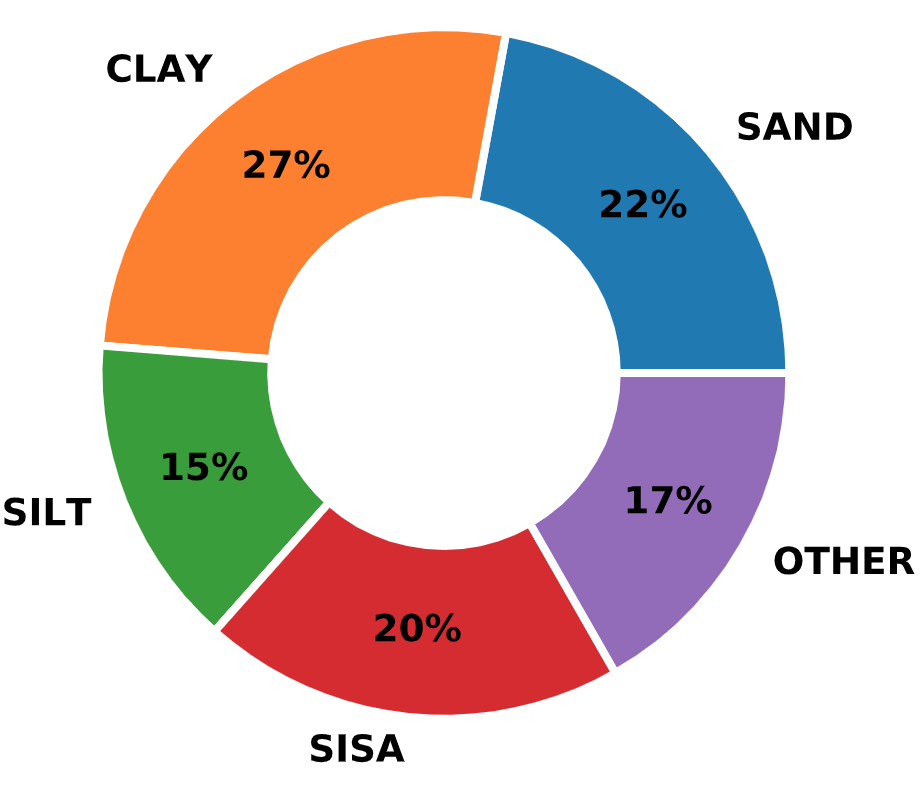
Fig. 2.13 Distribution of Soil Types in the FHWA DFLTD v.2¶
2.2.3.3. Data Format and ETL¶
DFLTD v.2 was developed in Microsoft Access 2013. The graphics utility Advanced Software Engineering’s Chartdirector was employed to design the forms, queries, and auxiliary tables required for data inquiry, viewing, and export. This utility allowed users to access data, but not to make any changes.
Fig. 2.14 FHWA DFLTD v.2 Database Organization (after Petek et al., 2016)¶
Fig. 2.14 shows the general structure of DFLTD v.2. The full ER diagram is presented in Fig. 2.15.
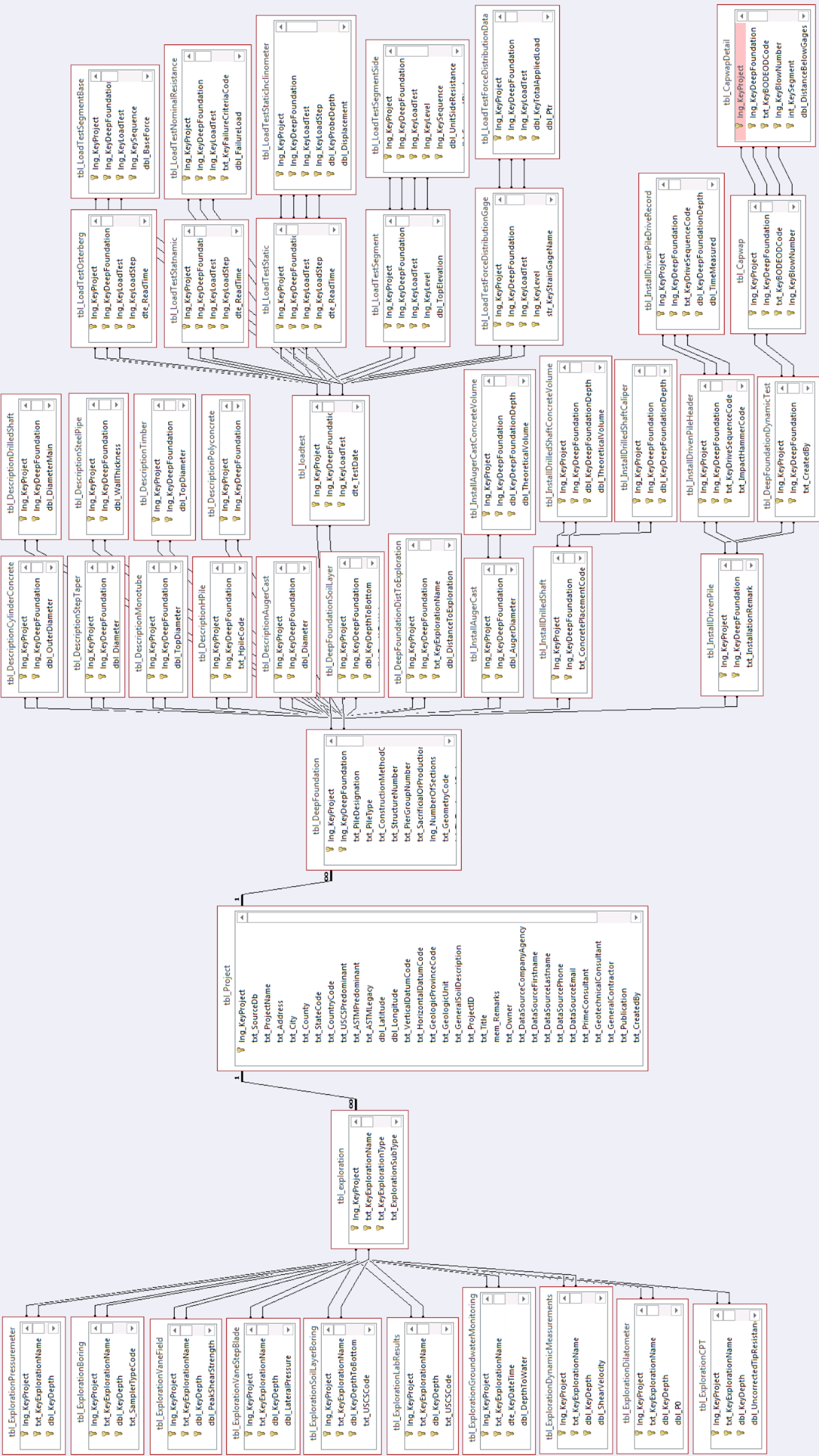
Fig. 2.15 E-R Diagram of FHWA DFLTD v.2 (exported from MS Access)¶
FHWA DFLTD v.2 was the largest database with over 900 projects and north of 1,500 pile load tests. It had, however, the poorest data quality. As an example, there were over 130 piles lacking basic information on diameter and/or length. Moreover, the database was developed for the 32-bit version of MS Access and would only work with 32-bit versions of MS Access which can be an issue for modern computers.
Data was organized in 46 tables (Fig. 2.15) with an additional 52 lookup tables. It appeared that proper database design was followed but was at times questionably cumbersome to query for data when, for example, size and shape information for piles was stored on different tables based on the type of the pile. The database contained a lot more data than the graphical user interface presented. Storing data in S.I. units was also questionable when it was clear that the original values were in English units. Unit conversion errors were discovered on multiple occasions. On a nutshell, it is evident that FHWA DFLTD v.2 was hastily compiled and no consideration was given on data quality and validation against basic engineering calculations.
The ETL process for FHWA DFLTD v.2 was the most complex out of all source databases used in this dissertation. Data on soil explorations was stored on multiple tables and there was little to no information on the location of soil borings with regard to pile locations. Projects had multiple records for soil explorations and also had multiple piles. Practically this meant that any (or none) of the borings corresponded to any (or none) one of the piles. By design, every record in NYU Pile Capacity must be unique. As such, when porting the FHWA DFLTD v.2 records into the NYU Pile Capacity database, all records were made unique, expanding the soil exploration and pile records by taking every possible combination of soil and pile data. As a result, the 1,500 load test records were expanded to 5,075 unique combinations of soil and pile instances.
In terms of soil explorations, FHWA DFLTD v.2 stored delineated soil profiles with few geotechnical properties in one table and the result of site and lab investigations in other tables. Using values per depth as a reference, data from all tables were combined by averaging the spt and lab data along the depth of a given soil layer. This helped in filling in a few gaps for engineering calculations but it was still not enough for the vast majority of the derived 5,075 records. The code for the ETL process is presented in Listing 2.5.
# -- Imports ---------------------------------------------------------------- #
import os
import pandas as pd
from tqdm import tqdm
from app import db
from .aux import data_owner
from app.models import Locations, Projects, Piles, LoadTests, StaticTests, \
InterpCapacities, Borings, Layers
pd.options.mode.chained_assignment = None
# -- File Paths ------------------------------------------------------------- #
FHWA_DATA_DIR = os.path.join('app', 'etl', '_data_sources', 'fhwa')
tbl_project_path = os.path.join(FHWA_DATA_DIR, 'tbl_Project.txt')
lkp_StateAndFHWADistrict_path = os.path.join(
FHWA_DATA_DIR, 'lkp_StateAndFHWADistrict.txt')
tbl_country_path = os.path.join(FHWA_DATA_DIR, 'lkp_Country.txt')
tbl_deepfoundation_path = os.path.join(FHWA_DATA_DIR, 'tbl_DeepFoundation.txt')
tbl_descaugercast_path = os.path.join(
FHWA_DATA_DIR, 'tbl_DescriptionAugerCast.txt')
tbl_descconccylinder_path = os.path.join(
FHWA_DATA_DIR, 'tbl_DescriptionCylinderConcrete.txt')
tbl_descdrilledshaft_path = os.path.join(
FHWA_DATA_DIR, 'tbl_DescriptionDrilledShaft.txt')
tbl_deschpile_path = os.path.join(FHWA_DATA_DIR, 'tbl_DescriptionHPile.txt')
tbl_descmonotube_path = os.path.join(
FHWA_DATA_DIR, 'tbl_DescriptionMonotube.txt')
tbl_descpolyconc_path = os.path.join(
FHWA_DATA_DIR, 'tbl_DescriptionPolyConcrete.txt')
tbl_descsteelpipe_path = os.path.join(
FHWA_DATA_DIR, 'tbl_DescriptionSteelPipe.txt')
tbl_descsteptaper_path = os.path.join(
FHWA_DATA_DIR, 'tbl_DescriptionStepTaper.txt')
tbl_desctimber_path = os.path.join(FHWA_DATA_DIR, 'tbl_DescriptionTimber.txt')
tbl_loadtest_path = os.path.join(FHWA_DATA_DIR, 'tbl_LoadTest.txt')
tbl_statictest_path = os.path.join(FHWA_DATA_DIR, 'tbl_LoadTestStatic.txt')
tbl_interp_path = os.path.join(
FHWA_DATA_DIR, 'tbl_LoadTestNominalResistance.txt')
tbl_exploration_path = os.path.join(FHWA_DATA_DIR, 'tbl_Exploration.txt')
tbl_explsoilboring_path = os.path.join(
FHWA_DATA_DIR, 'tbl_ExplorationSoilLayerBoring.txt')
tbl_explboring_path = os.path.join(FHWA_DATA_DIR, 'tbl_ExplorationBoring.txt')
tbl_expllab_path = os.path.join(FHWA_DATA_DIR, 'tbl_ExplorationLabResults.txt')
# -- Creating Pandas DataFrames --------------------------------------------- #
tbl_project = pd.read_csv(tbl_project_path)
lkp_stateandfhwadistrict = pd.read_csv(lkp_StateAndFHWADistrict_path)
tbl_country = pd.read_csv(tbl_country_path)
tbl_deepfoundation = pd.read_csv(tbl_deepfoundation_path)
tbl_descaugercast = pd.read_csv(tbl_descaugercast_path)
tbl_descconccylinder = pd.read_csv(tbl_descconccylinder_path)
tbl_descdrilledshaft = pd.read_csv(tbl_descdrilledshaft_path)
tbl_deschpile = pd.read_csv(tbl_deschpile_path)
tbl_descmonotube = pd.read_csv(tbl_descmonotube_path)
tbl_descpolyconc = pd.read_csv(tbl_descpolyconc_path)
tbl_descsteelpipe = pd.read_csv(tbl_descsteelpipe_path)
tbl_descsteptaper = pd.read_csv(tbl_descsteptaper_path)
tbl_desctimber = pd.read_csv(tbl_desctimber_path)
tbl_loadtest = pd.read_csv(tbl_loadtest_path)
tbl_statictest = pd.read_csv(tbl_statictest_path, low_memory=False)
tbl_interp = pd.read_csv(tbl_interp_path)
tbl_exploration = pd.read_csv(tbl_exploration_path)
tbl_explsoilboring = pd.read_csv(tbl_explsoilboring_path)
tbl_explsoilboring = tbl_explsoilboring[
tbl_explsoilboring['dbl_KeyDepthToBottom'] != 0]
tbl_explsoilboring.reset_index(inplace=True, drop=True)
tbl_explsoilboring['txt_KeyExplorationName'] = tbl_explsoilboring[
'txt_KeyExplorationName'].str.strip()
tbl_explboring = pd.read_csv(tbl_explboring_path)
tbl_explboring['txt_KeyExplorationName'] = tbl_explboring[
'txt_KeyExplorationName'].str.strip()
tbl_expllab = pd.read_csv(tbl_expllab_path)
tbl_expllab['txt_KeyExplorationName'] = tbl_expllab[
'txt_KeyExplorationName'].str.strip()
# -- Helper Functions ------------------------------------------------------- #
def add_loc_proj(i, warning=None):
""" Compiles location and project data given an index for the tbl_project
DataFrame
"""
# -- Adding Location Data ----------------------------------------------- #
state_code = tbl_project['txt_StateCode'][i]
state_name = lkp_stateandfhwadistrict.loc[
lkp_stateandfhwadistrict['txt_StateCode'] == state_code,
'txt_StateName'].values[0] if not pd.isna(state_code) else None
country_code = tbl_project['txt_CountryCode'][i]
country_name = tbl_country.loc[
tbl_country['txt_CountryCode'] == country_code,
'txt_CountryDescription'].values[0]
loc = Locations(
address=tbl_project['txt_Address'][i]
if not pd.isna(tbl_project['txt_Address'][i]) else None,
city=tbl_project['txt_City'][i]
if not pd.isna(tbl_project['txt_City'][i]) else None,
county=tbl_project['txt_County'][i]
if not pd.isna(tbl_project['txt_County'][i]) else None,
state=state_name,
country=country_name,
latitude=tbl_project['dbl_Latitude'][i]
if abs(tbl_project['dbl_Latitude'][i]) < 100 else None,
longitude=tbl_project['dbl_Longitude'][i]
if abs(tbl_project['dbl_Longitude'][i]) < 100 else None,
)
db.session.add(loc)
# -- Adding Project Data ------------------------------------------------ #
prj = Projects(
location=loc,
user_id=data_owner().id,
source_db='FHWA DFLTD v.2',
source_id=int(tbl_project['lng_KeyProject'][i]),
description=tbl_project['mem_Remarks'][i]
if not pd.isna(tbl_project['mem_Remarks'][i]) else None,
site_name=tbl_project['txt_ProjectName'][i]
if not pd.isna(tbl_project['txt_ProjectName'][i]) else None,
source_ref=tbl_project['txt_Publication'][i]
if not pd.isna(tbl_project['txt_Publication'][i]) else None,
contractor=tbl_project['txt_GeneralContractor'][i]
if not pd.isna(tbl_project['txt_GeneralContractor'][i]) else None,
number=tbl_project['txt_ProjectID'][i]
if not pd.isna(tbl_project['txt_ProjectID'][i]) else None,
title=tbl_project['txt_Title'][i]
if not pd.isna(tbl_project['txt_Title'][i]) else None,
date_added=pd.to_datetime(
tbl_project['dte_AddDate'][i] if not
pd.isna(tbl_project['dte_AddDate'][i]) else None),
warning=warning
)
return prj
def pile_dims(ptype, prj_id, pile_id):
""" Fetches relevant pile data from the "Description" tables for each
pile type
"""
diameter = None
wall_thickness = None
modulus = None
weight_ft = None
cross_area = None
shape = None
square_circ = None
circumference = None
conc_filled = None
if ptype in ('CC', 'RC'):
d_series = tbl_descconccylinder[
(tbl_descconccylinder['lng_KeyProject'] == prj_id) &
(tbl_descconccylinder['lng_KeyDeepFoundation'] == pile_id)
]['dbl_OuterDiameter']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
t_series = tbl_descconccylinder[
(tbl_descconccylinder['lng_KeyProject'] == prj_id) &
(tbl_descconccylinder['lng_KeyDeepFoundation'] == pile_id)
]['dbl_WallThickness']
if not t_series.empty:
wall_thickness = t_series.values[0] * 0.0393701
m_series = tbl_descconccylinder[
(tbl_descconccylinder['lng_KeyProject'] == prj_id) &
(tbl_descconccylinder['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CompositeModulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
w_series = tbl_descconccylinder[
(tbl_descconccylinder['lng_KeyProject'] == prj_id) &
(tbl_descconccylinder['lng_KeyDeepFoundation'] == pile_id)
]['dbl_WeightPerUnitLength']
if not w_series.empty and not pd.isna(w_series.values[0]):
weight_ft = w_series.values[0] * 0.67
elif ptype in ('MI', 'BC', 'FC', 'SP', 'AC'):
if prj_id != 707:
d_series = tbl_descdrilledshaft[
(tbl_descdrilledshaft['lng_KeyProject'] == prj_id) &
(tbl_descdrilledshaft['lng_KeyDeepFoundation'] == pile_id)
]['dbl_DiameterMain']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
m_series = tbl_descdrilledshaft[
(tbl_descdrilledshaft['lng_KeyProject'] == prj_id) &
(tbl_descdrilledshaft['lng_KeyDeepFoundation'] == pile_id)
]['dbl_ConcreteModulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
a_series = tbl_descdrilledshaft[
(tbl_descdrilledshaft['lng_KeyProject'] == prj_id) &
(tbl_descdrilledshaft['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CrossSectionArea']
if not a_series.empty:
cross_area = a_series.values[0] * 1.5500031000062e-03
else:
d_series = tbl_descaugercast[
(tbl_descaugercast['lng_KeyProject'] == prj_id) &
(tbl_descaugercast['lng_KeyDeepFoundation'] == pile_id)
]['dbl_Diameter']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
elif ptype == 'SH':
d_series = tbl_deschpile[
(tbl_deschpile['lng_KeyProject'] == prj_id) &
(tbl_deschpile['lng_KeyDeepFoundation'] == pile_id)
]['dbl_FlangeWidth']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
w_series = tbl_deschpile[
(tbl_deschpile['lng_KeyProject'] == prj_id) &
(tbl_deschpile['lng_KeyDeepFoundation'] == pile_id)
]['dbl_WeightPerUnitLength']
if not w_series.empty and not pd.isna(w_series.values[0]):
weight_ft = w_series.values[0] * 0.67
m_series = tbl_deschpile[
(tbl_deschpile['lng_KeyProject'] == prj_id) &
(tbl_deschpile['lng_KeyDeepFoundation'] == pile_id)
]['dbl_SteelModulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
sh_series = tbl_deschpile[
(tbl_deschpile['lng_KeyProject'] == prj_id) &
(tbl_deschpile['lng_KeyDeepFoundation'] == pile_id)
]['txt_HpileCode']
if not sh_series.empty:
shape = sh_series.values[0]
a_series = tbl_deschpile[
(tbl_deschpile['lng_KeyProject'] == prj_id) &
(tbl_deschpile['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CrossSectionArea']
if not a_series.empty:
cross_area = a_series.values[0] * 1.5500031000062e-03
depth = tbl_deschpile[
(tbl_deschpile['lng_KeyProject'] == prj_id) &
(tbl_deschpile['lng_KeyDeepFoundation'] == pile_id)
]['dbl_DepthSection']
if not depth.empty:
square_circ = (2 * diameter + 2 * depth.values[0] * 0.0393701) / 12
circ = tbl_deschpile[
(tbl_deschpile['lng_KeyProject'] == prj_id) &
(tbl_deschpile['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CoatingArea']
if not circ.empty and not pd.isna(circ.values[0]):
circumference = circ.values[0] * 0.00328084
t_series = tbl_deschpile[
(tbl_deschpile['lng_KeyProject'] == prj_id) &
(tbl_deschpile['lng_KeyDeepFoundation'] == pile_id)
]['dbl_WebThickness']
if not t_series.empty:
wall_thickness = t_series.values[0] * 0.0393701
elif ptype == 'M':
d_series = tbl_descmonotube[
(tbl_descmonotube['lng_KeyProject'] == prj_id) &
(tbl_descmonotube['lng_KeyDeepFoundation'] == pile_id)
]['dbl_TopDiameter']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
t_series = tbl_descmonotube[
(tbl_descmonotube['lng_KeyProject'] == prj_id) &
(tbl_descmonotube['lng_KeyDeepFoundation'] == pile_id)
]['dbl_Gauge']
if not t_series.empty:
wall_thickness = t_series.values[0] * 0.0393701
elif ptype in ('OC', 'SC'):
if prj_id == 460 and pile_id == 1:
d_series = tbl_descconccylinder[
(tbl_descconccylinder['lng_KeyProject'] == prj_id) &
(tbl_descconccylinder['lng_KeyDeepFoundation'] == pile_id)
]['dbl_OuterDiameter']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
m_series = tbl_descconccylinder[
(tbl_descconccylinder['lng_KeyProject'] == prj_id) &
(tbl_descconccylinder['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CompositeModulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
w_series = tbl_descconccylinder[
(tbl_descconccylinder['lng_KeyProject'] == prj_id) &
(tbl_descconccylinder['lng_KeyDeepFoundation'] == pile_id)
]['dbl_WeightPerUnitLength']
if not w_series.empty and not pd.isna(w_series.values[0]):
weight_ft = w_series.values[0] * 0.67
else:
if ptype == 'SC':
d_series = tbl_descpolyconc[
(tbl_descpolyconc['lng_KeyProject'] == prj_id) &
(tbl_descpolyconc['lng_KeyDeepFoundation'] == pile_id)
]['dbl_SideLength']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
else:
d_series = tbl_descpolyconc[
(tbl_descpolyconc['lng_KeyProject'] == prj_id) &
(tbl_descpolyconc['lng_KeyDeepFoundation'] == pile_id)
]['dbl_EquivalentDiameter']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
circ = tbl_descpolyconc[
(tbl_descpolyconc['lng_KeyProject'] == prj_id) &
(tbl_descpolyconc['lng_KeyDeepFoundation'] == pile_id)
]['dbl_Perimeter']
if not circ.empty and not pd.isna(circ.values[0]):
circumference = circ.values[0] * 0.00328084
a_series = tbl_descpolyconc[
(tbl_descpolyconc['lng_KeyProject'] == prj_id) &
(tbl_descpolyconc['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CrossSectionArea']
if not a_series.empty:
cross_area = a_series.values[0] * 1.5500031000062e-03
m_series = tbl_descpolyconc[
(tbl_descpolyconc['lng_KeyProject'] == prj_id) &
(tbl_descpolyconc['lng_KeyDeepFoundation'] == pile_id)
]['dbl_ConcreteModulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
elif ptype in ('SPO', 'SPC'):
t_series = tbl_descsteelpipe[
(tbl_descsteelpipe['lng_KeyProject'] == prj_id) &
(tbl_descsteelpipe['lng_KeyDeepFoundation'] == pile_id)
]['dbl_WallThickness']
if not t_series.empty:
wall_thickness = t_series.values[0] * 0.0393701
d_series = tbl_descsteelpipe[
(tbl_descsteelpipe['lng_KeyProject'] == prj_id) &
(tbl_descsteelpipe['lng_KeyDeepFoundation'] == pile_id)
]['dbl_OuterDiameter']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
a_series = tbl_descsteelpipe[
(tbl_descsteelpipe['lng_KeyProject'] == prj_id) &
(tbl_descsteelpipe['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CrossSectionArea']
if not a_series.empty:
cross_area = a_series.values[0] * 1.5500031000062e-03
w_series = tbl_descsteelpipe[
(tbl_descsteelpipe['lng_KeyProject'] == prj_id) &
(tbl_descsteelpipe['lng_KeyDeepFoundation'] == pile_id)
]['dbl_WeightPerUnitLength']
if not w_series.empty and not pd.isna(w_series.values[0]):
weight_ft = w_series.values[0] * 0.67
if prj_id < 1000 or prj_id == 1050:
m_series = tbl_descsteelpipe[
(tbl_descsteelpipe['lng_KeyProject'] == prj_id) &
(tbl_descsteelpipe['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CompositeModulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
else:
m_series = tbl_descsteelpipe[
(tbl_descsteelpipe['lng_KeyProject'] == prj_id) &
(tbl_descsteelpipe['lng_KeyDeepFoundation'] == pile_id)
]['dbl_SteelModulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
conc_filled_series = tbl_descsteelpipe[
(tbl_descsteelpipe['lng_KeyProject'] == prj_id) &
(tbl_descsteelpipe['lng_KeyDeepFoundation'] == pile_id)
]['txt_ConcreteFilledYN']
if not conc_filled_series.empty and conc_filled_series.values[0] == 'Y':
conc_filled = True
elif ptype == 'ST':
d_series = tbl_descsteptaper[
(tbl_descsteptaper['lng_KeyProject'] == prj_id) &
(tbl_descsteptaper['lng_KeyDeepFoundation'] == pile_id)
]['dbl_Diameter']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
conc_filled_series = tbl_descsteptaper[
(tbl_descsteptaper['lng_KeyProject'] == prj_id) &
(tbl_descsteptaper['lng_KeyDeepFoundation'] == pile_id)
]['txt_ConcreteFilledYN']
if not conc_filled_series.empty and conc_filled_series.values[0] == 'Y':
conc_filled = True
a_series = tbl_descsteptaper[
(tbl_descsteptaper['lng_KeyProject'] == prj_id) &
(tbl_descsteptaper['lng_KeyDeepFoundation'] == pile_id)
]['dbl_CrossSectionArea']
if not a_series.empty:
cross_area = a_series.values[0] * 1.5500031000062e-03
m_series = tbl_descsteptaper[
(tbl_descsteptaper['lng_KeyProject'] == prj_id) &
(tbl_descsteptaper['lng_KeyDeepFoundation'] == pile_id)
]['dbl_Modulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
elif ptype == 'T':
d_series = tbl_desctimber[
(tbl_desctimber['lng_KeyProject'] == prj_id) &
(tbl_desctimber['lng_KeyDeepFoundation'] == pile_id)
]['dbl_TopDiameter']
if not d_series.empty:
diameter = d_series.values[0] * 0.0393701
m_series = tbl_desctimber[
(tbl_desctimber['lng_KeyProject'] == prj_id) &
(tbl_desctimber['lng_KeyDeepFoundation'] == pile_id)
]['dbl_Modulus']
if not m_series.empty and not pd.isna(m_series.values[0]):
modulus = m_series.values[0] * 1.4503773773e-07
return {'diameter': diameter, 'wall_thickness': wall_thickness,
'modulus': modulus, 'weight_ft': weight_ft,
'cross_area': cross_area, 'shape': shape,
'square_circ': square_circ, 'circumference': circumference,
'conc_filled': conc_filled}
def add_pile_data(i_pile, prj_id, pile_id, prj):
""" Compiles pile data given an index for the tbl_deepfoundation
DataFrame
"""
org_ptype = tbl_deepfoundation['txt_PileType'][i_pile]
ptype = pile_types[
tbl_deepfoundation['txt_PileType'][i_pile]]['type']
pshape = pile_types[
tbl_deepfoundation['txt_PileType'][i_pile]]['shape']
pshape = pshape if ptype != 'HPIL' else pile_dims(
org_ptype, prj_id, pile_id)['shape']
plength = tbl_deepfoundation[
'dbl_TotalLength'][i_pile] * 0.00328084
str_num = tbl_deepfoundation['txt_StructureNumber'][i_pile]
str_num = str_num + '; ' if not pd.isna(str_num) else ''
pier_num = tbl_deepfoundation['txt_PierGroupNumber'][i_pile]
pier_num = pier_num if not pd.isna(pier_num) else ''
conc_filled = pile_dims(org_ptype, prj_id, pile_id)['conc_filled']
conc_filled = '(CONCRETE FILLED) ' if conc_filled else ''
pile_remarks = conc_filled + str_num + pier_num
pile_remarks = None if pile_remarks == '' else pile_remarks
pmodulus = pile_dims(org_ptype, prj_id, pile_id)['modulus']
weight_ft = pile_dims(org_ptype, prj_id, pile_id)['weight_ft']
pile = Piles(
project=prj,
type=ptype,
shape=pshape,
length=round(plength, 1) if not pd.isna(plength) else None,
emb_length=round(tbl_deepfoundation[
'dbl_EmbeddedLength'][i_pile] * 0.00328084, 1)
if not pd.isna(tbl_deepfoundation['dbl_EmbeddedLength'][i_pile])
else None,
remarks=pile_remarks,
name=tbl_deepfoundation['txt_PileDesignation'][i_pile],
tapered=True if tbl_deepfoundation[
'txt_GeometryCode'][i_pile] == 'V' else None,
vibro=True if tbl_deepfoundation[
'txt_ConstructionMethodCode'][i_pile] in ('VDID', 'VD')
else None,
jetted=True if tbl_deepfoundation[
'txt_ConstructionMethodCode'][i_pile] == 'JETID'
else None,
toe_elevation=tbl_deepfoundation[
'dbl_TipElevation'][i_pile] * 0.00328084
if not pd.isna(tbl_deepfoundation[
'dbl_TipElevation'][i_pile]) else None,
head_elevation=tbl_deepfoundation[
'dbl_TopElevation'][i_pile] * 0.00328084
if not pd.isna(tbl_deepfoundation[
'dbl_TopElevation'][i_pile]) else None,
diameter=round(pile_dims(org_ptype, prj_id, pile_id)['diameter'], 1)
if not pd.isna(pile_dims(org_ptype, prj_id, pile_id)['diameter'])
else None,
wall_thickness=pile_dims(
org_ptype, prj_id, pile_id)['wall_thickness']
if not pd.isna(pile_dims(
org_ptype, prj_id, pile_id)['wall_thickness']) else None,
modulus=int(pmodulus) if pmodulus else None,
weight=int(weight_ft * plength) if weight_ft else None,
cross_area=round(pile_dims(
org_ptype, prj_id, pile_id)['cross_area'], 1) if not pd.isna(
pile_dims(org_ptype, prj_id, pile_id)['cross_area']) else None,
square_circ=pile_dims(
org_ptype, prj_id, pile_id)['square_circ']
if not pd.isna(pile_dims(
org_ptype, prj_id, pile_id)['square_circ']) else None,
circumference=pile_dims(
org_ptype, prj_id, pile_id)['circumference']
if not pd.isna(pile_dims(
org_ptype, prj_id, pile_id)['circumference']) else None,
)
return pile
def add_load_test_data(i_lt, pile):
""" Compiles load_test data given an index for the tbl_LoadTest DataFrame
"""
lt_test_code = tbl_loadtest['txt_LoadTestCode'][i_lt]
lt_dir_code = tbl_loadtest['txt_LoadTypeCode'][i_lt]
lt_dir_code = lt_dir_code if not pd.isna(lt_dir_code) else ''
lt_contractor = tbl_loadtest['txt_LoadTestSubcontractor'][i_lt]
lt_contractor = lt_contractor if not pd.isna(lt_contractor) else None
astm_lt_type = tbl_loadtest['txt_ASTMProcedureCode'][i_lt]
load_test = LoadTests(
pile=pile,
direction=lt_dir[lt_test_code + lt_dir_code],
date_tested=pd.to_datetime(
tbl_loadtest['dte_TestDate'][i_lt] if not
pd.isna(tbl_loadtest['dte_TestDate'][i_lt]) else None),
setup_time=tbl_loadtest['dbl_SetupDays'][i_lt]
if not pd.isna(tbl_loadtest['dbl_SetupDays'][i_lt]) else None,
tested_by=lt_contractor if lt_contractor != 'Unknown' else None,
static_type=test_type[astm_lt_type] if not
pd.isna(astm_lt_type) else None
)
return load_test
def add_static_test_data(prj_id, pile_id, test_id, load_test):
""" Compiles load_test data given an index for the tbl_LoadTestStatic
DataFrame
"""
slt_points = tbl_statictest[
(tbl_statictest.lng_KeyProject == prj_id) &
(tbl_statictest.lng_KeyDeepFoundation == pile_id) &
(tbl_statictest.lng_KeyLoadTest == test_id)]
for p in slt_points.index:
index = int(slt_points['lng_KeyLoadStep'][p])
q_generic = slt_points['dbl_TotalAppliedLoadGeneric'][p]
q_cell = slt_points['dbl_TotalAppliedLoadCell'][p]
q_jack = slt_points['dbl_TotalAppliedLoadJack'][p]
q_strain = slt_points['dbl_TotalAppliedLoadStrainGage'][p]
if not pd.isna(q_generic):
q = q_generic * 2.24808943e-04
load_type = 'Generic'
elif not pd.isna(q_cell):
q = q_cell * 2.24808943e-04
load_type = 'Load Cell'
elif not pd.isna(q_jack):
q = q_jack * 2.24808943e-04
load_type = 'Hydraulic Jack'
elif not pd.isna(q_strain):
q = q_strain * 2.24808943e-04
load_type = 'Strain Gage'
else:
q = None
load_type = None
s_generic = slt_points['dbl_DisplGeneric'][p]
s_head = slt_points['dbl_DisplPileHeadSurvey'][p]
s_dial = slt_points['dbl_DisplDialGage'][p]
s_level = slt_points['dbl_DisplLiquidLevelGage'][p]
if not pd.isna(s_generic):
s = s_generic * -0.0393701
displ_type = 'Generic'
elif not pd.isna(s_head):
s = s_head * -0.0393701
displ_type = 'Pile Head Survey'
elif not pd.isna(s_dial):
s = s_dial * -0.0393701
displ_type = 'Dial Gage'
elif not pd.isna(s_level):
s = s_level * -0.0393701
displ_type = 'Liquid Level Gage'
else:
s = None
displ_type = None
slt_point = StaticTests(
load_test=load_test,
index=index,
load=q,
load_type=load_type,
displacement=s,
displ_type=displ_type
)
db.session.add(slt_point)
def add_interp_data(prj_id, pile_id, test_id, load_test):
""" Compiles interpreted capacity data given an index for the
tbl_LoadTestNominalResistance DataFrame
"""
interp_capacities = tbl_interp[
(tbl_interp.lng_KeyProject == prj_id) &
(tbl_interp.lng_KeyDeepFoundation == pile_id) &
(tbl_interp.lng_KeyLoadTest == test_id)]
for c in interp_capacities.index:
interp_code = interp_capacities[
'txt_KeyFailureCriteriaCode'][c]
interp_method = interp_type[interp_code] if not \
pd.isna(interp_code) else 'Unknown/Not Specified'
interp_load = interp_capacities[
'dbl_FailureLoad'][c] * 2.24808943e-04
interp_disp = interp_capacities[
'dbl_Displacement'][c] * 0.0393701
interp_capacity = InterpCapacities(
load_test=load_test,
load=interp_load,
displacement=interp_disp,
type=interp_method,
origin='source DB'
)
db.session.add(interp_capacity)
def add_expl_data(i_exp, expl_id, prj):
""" Compiles boring data from the tbl_Exploration DataFrame
"""
exp_remarks = tbl_exploration['mem_Remarks'][i_exp] \
if not pd.isna(tbl_exploration['mem_Remarks'][i_exp]) \
else None
exp_ewt = tbl_exploration['dbl_DepthToWaterStatic'][i_exp] * 0.00328084 \
if not pd.isna(
tbl_exploration['dbl_DepthToWaterStatic'][i_exp]) else None
exp_predom = tbl_exploration[
'txt_USCSCodePredominant'][i_exp] if not pd.isna(
tbl_exploration['txt_USCSCodePredominant'][i_exp]) else 'NA'
exp_predom = uscs_predom[exp_predom]
exp_type = tbl_exploration['txt_KeyExplorationType'][i_exp]
exp_elev = tbl_exploration['dbl_GroundElevation'][i_exp] * 0.00328084 \
if not pd.isna(
tbl_exploration['dbl_GroundElevation'][i_exp]) else None
exploration = Borings(
name=expl_id,
project=prj,
remarks=exp_remarks,
ewt=exp_ewt,
predom_soil=exp_predom,
type=exp_type,
elevation=exp_elev)
return exploration
def add_layer_data(prj_id, expl_id, exploration):
""" Compiles layer data from the tbl_ExplorationSoilLayerBoring DataFrame
"""
layers = tbl_explsoilboring[
(tbl_explsoilboring.lng_KeyProject == prj_id) &
(tbl_explsoilboring.txt_KeyExplorationName == expl_id)]
# add new column with layer numbers
layers['layer'] = [i for i in range(1, len(layers.index) + 1)]
# get SPT data
spt_data = tbl_explboring[
(tbl_explboring.lng_KeyProject == prj_id) &
(tbl_explboring.txt_KeyExplorationName == expl_id)]
if not spt_data.empty and not layers.empty:
spt_depths = spt_data.dbl_KeyDepth
layer_i = []
max_d = layers['dbl_KeyDepthToBottom'].values[-1]
for d in spt_depths:
if d <= max_d:
layr = layers[
layers.dbl_KeyDepthToBottom >= d]['layer'].values[0]
else:
layr = None
layer_i.append(layr)
spt_data['layer'] = layer_i
avg_spt = spt_data[
['layer', 'dbl_FieldBlowCount']].groupby('layer').agg('mean')
else:
avg_spt = pd.DataFrame()
# get lab data
lab_data = tbl_expllab[
(tbl_expllab.lng_KeyProject == prj_id) &
(tbl_expllab.txt_KeyExplorationName == expl_id)]
if not lab_data.empty and not layers.empty:
lab_depths = lab_data.dbl_KeyDepth
layer_i = []
max_d = layers['dbl_KeyDepthToBottom'].values[-1]
for d in lab_depths:
if d <= max_d:
layr = layers[
layers.dbl_KeyDepthToBottom >= d]['layer'].values[0]
else:
layr = None
layer_i.append(layr)
lab_data['layer'] = layer_i
avg_lab = lab_data[
['layer', 'dbl_MoistureContent', 'dbl_TotalUnitWeight',
'dbl_LiquidLimit', 'dbl_PlasticityIndex', 'dbl_Cohesion']
].groupby('layer').agg('mean')
else:
avg_lab = pd.DataFrame()
for i in layers.index:
index = int(layers.layer[i])
if index == 1:
height = tbl_explsoilboring['dbl_KeyDepthToBottom'][i] * 0.00328084
else:
height = (tbl_explsoilboring['dbl_KeyDepthToBottom'][i]
- tbl_explsoilboring['dbl_KeyDepthToBottom'][i-1]) \
* 0.00328084
soil_type = tbl_explsoilboring['txt_PrimarySoilDescriptionCode'][i] \
if not pd.isna(
tbl_explsoilboring['txt_PrimarySoilDescriptionCode'][i]) else None
soil_type = primary_explsoil[soil_type] if soil_type else None
uscs_type = tbl_explsoilboring['txt_USCSCode'][i] if not \
pd.isna(tbl_explsoilboring['txt_USCSCode'][i]) else None
if not soil_type and uscs_type:
soil_type = uscs_type
description = tbl_explsoilboring['txt_LayerDescription'][i] \
if not pd.isna(tbl_explsoilboring['txt_LayerDescription'][i]) \
else None
nval = tbl_explsoilboring['dbl_BlowCountInterpreted'][i] \
if not pd.isna(tbl_explsoilboring['dbl_BlowCountInterpreted'][i]) \
else None
nval_from_avg_spt = avg_spt[avg_spt.index == index]
if not nval and not nval_from_avg_spt.empty:
nval = nval_from_avg_spt.values[0][0] if not pd.isna(
nval_from_avg_spt.values[0][0]) else None
angle = tbl_explsoilboring['dbl_FrictionAngleInterpreted'][i] \
if not pd.isna(
tbl_explsoilboring['dbl_FrictionAngleInterpreted'][i]) else None
data_from_avg_lab = avg_lab[avg_lab.index == index]
cohesion = tbl_explsoilboring['dbl_CohesionInterpreted'][i] \
* 2.0885434273e-05 if not pd.isna(
tbl_explsoilboring['dbl_CohesionInterpreted'][i]) else None
if not cohesion and not data_from_avg_lab.empty:
cohesion = data_from_avg_lab.values[0][4] * 2.0885434273e-05 \
if not pd.isna(data_from_avg_lab.values[0][4]) else None
if cohesion:
cohesion = cohesion if cohesion < 99 else None
tuw = tbl_explsoilboring['dbl_UnitWeightInterpreted'][i] * 0.062428 \
if not pd.isna(tbl_explsoilboring['dbl_UnitWeightInterpreted'][i]) \
else None
if not tuw and not data_from_avg_lab.empty:
tuw = data_from_avg_lab.values[0][1] * 0.062428 if not pd.isna(
data_from_avg_lab.values[0][1]) else None
if not data_from_avg_lab.empty and not pd.isna(
data_from_avg_lab.values[0][0]):
water_content = int(data_from_avg_lab.values[0][0])
else:
water_content = None
if not data_from_avg_lab.empty and not pd.isna(
data_from_avg_lab.values[0][2]):
liquid_limit = int(data_from_avg_lab.values[0][2])
else:
liquid_limit = None
if not data_from_avg_lab.empty and not pd.isna(
data_from_avg_lab.values[0][3]):
plasticity = int(data_from_avg_lab.values[0][3])
else:
plasticity = None
layer = Layers(
boring=exploration,
index=index,
soil_type=soil_type,
height=height,
description=description,
nval=nval,
ssuu=cohesion,
friction_angle=angle,
tuw=tuw,
water_content=water_content,
liquid_limit=liquid_limit,
plasticity=plasticity
)
db.session.add(layer)
# -- Main Import Function --------------------------------------------------- #
def load_fhwa_records():
""" Iterates through source files and adds the FHWA DFLTD records to the
database
"""
print('--- Importing FHWA DFLTD v.2 records ---')
for i in tqdm(range(len(tbl_project))):
prj_id = tbl_project['lng_KeyProject'][i]
expl_in_project = tbl_exploration[
tbl_exploration.lng_KeyProject == prj_id].index
for i_exp in expl_in_project:
expl_id = tbl_exploration['txt_KeyExplorationName'][i_exp]
piles_in_project = tbl_deepfoundation[
tbl_deepfoundation.lng_KeyProject == prj_id].index
for i_pile in piles_in_project:
pile_id = tbl_deepfoundation['lng_KeyDeepFoundation'][i_pile]
tests_for_pile = tbl_loadtest[
(tbl_loadtest.lng_KeyProject == prj_id) &
(tbl_loadtest.lng_KeyDeepFoundation == pile_id)
].index
for i_lt in tests_for_pile:
test_id = tbl_loadtest['lng_KeyLoadTest'][i_lt]
# -- Adding Project Data -------------------------------- #
if len(piles_in_project) > 1 and len(expl_in_project) < 2:
wrn = 'Expanded from a project with multiple piles '\
'and/or retests'
prj = add_loc_proj(i, wrn)
elif len(piles_in_project) < 2 and len(expl_in_project) > 1:
wrn = 'Expanded from a project with multiple '\
'explorations'
prj = add_loc_proj(i, wrn)
elif len(piles_in_project) > 1 and len(expl_in_project) > 1:
wrn = 'Expanded from a project with multiple '\
'explorations and multiple piles/retests'
prj = add_loc_proj(i, wrn)
else:
prj = add_loc_proj(i)
db.session.add(prj)
# -- Adding Exploration Data ---------------------------- #
exploration = add_expl_data(i_exp, expl_id, prj)
db.session.add(exploration)
# -- Adding Layer Data ---------------------------------- #
add_layer_data(prj_id, expl_id, exploration)
# -- Adding Pile Data ----------------------------------- #
pile = add_pile_data(i_pile, prj_id, pile_id, prj)
db.session.add(pile)
# -- Adding Load Test Data ------------------------------ #
load_test = add_load_test_data(i_lt, pile)
db.session.add(load_test)
# -- Adding Static Test Data ---------------------------- #
add_static_test_data(prj_id, pile_id, test_id, load_test)
# -- Adding Interpreted Data ---------------------------- #
add_interp_data(prj_id, pile_id, test_id, load_test)
db.session.commit()
2.2.4. LTRC LAPLTD¶
2.2.4.1. Background¶
This database was developed as part of a study on the calibration of the Gates pile driving formula (Tavera et. al, 2016) by the Louisiana Transportation Research Center (LTRC). The database was called the LADOTD Pile Load Test Database (LAPLTD) and it contains records from the state of Louisiana only.
Design of the LTRC LAPLTD was based on the Louisiana Department of Transportation and Development (DOTD) Test Pile database that was developed by the DOTD Pavement and Geotechnical Design Section. LTRC LAPLTD contains data obtained only from DOTD pile load test case histories from the following three sources:
DOTD Test Pile Database - 863 records
FHWA Deep Foundation Load Test Database (DFLTD v.1) (Louisiana case histories only) - 198 records
LTRC 14-1GT Research Project - 146 records
Significant modifications were made to LTRC LAPLTD by adding new information fields, reorganizing data, and implementing data management controls to reduce the chances of data corruption.
A major limitation though, was that LTRC LAPLTD contained no information on geotechnical data and site investigations other than a label for the predominant soil at the pile location and the names of nearest borings or CPT soundings per pile. LTRC LAPLTD was however successful in assisting to provide reasonable recommendations on the improvement of pile driving formulas as well as revised resistance factors for LRFD.
Description |
Quantity |
|---|---|
Projects |
194 |
Piles Tested |
804 |
Static Load Tests |
252 |
EOID Dynamic Load Tests (with CAPWAP) |
183 |
BOR Dynamic Load Tests (with CAPWAP) |
751 |
Total Dynamic Load Tests |
934 |
Total Static & Dynamic Load Tests |
1,186 |
Finally, it must be noted that one of the data sources of LTRC LAPLTD, the DOTD Test Pile Database, contributed 269 pile load tests to the original version of the FHWA DFLTD (Kalavar and Ealy, 2000). The DOTD data was collected and documented in an LTRC report (Tumay and Titi, 1998). The DFLTD database released to all state DOTs and FHWA offices in 2014 indicates that 245 load tests were included in the final version of the DFLTD (Tavera et. al, 2016).
2.2.4.2. Database Statistics¶
As per the corresponding LTRC Report 561 (Tavera et. al, 2016), a significant amount of effort was expended collecting pile load test data, performing QA reviews of the data, cleansing the data, and standardizing the data. These efforts were made to facilitate the collection of quality load test data for use in conducting the research on the calibration of the pile driving formulas as well as facilitating future research projects.
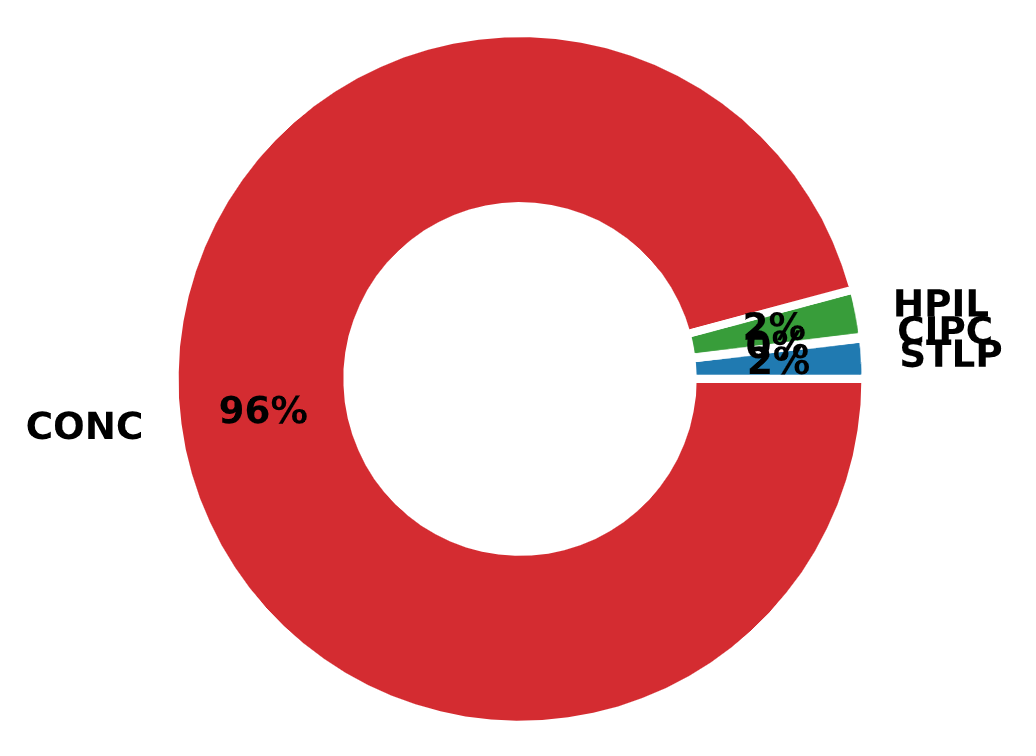
Fig. 2.16 Distribution of Pile Types in LTRC LAPLTD¶
Table 2.1 presents a summary of the number of records in LTRC LAPLTD. It is clear that the dynamic outnumber the static test records (934 vs. 252) for a total of 1,186 combined test records. It must be noted that during the ETL process of porting the LTRC LAPLTD records in NYU Pile Capacity, the total number was 1,223 and not 1,186.
85% of the piles load tested were in southern Louisiana. The largest concentration of load tested piles were in the Lafourche parish (57% of the piles). East Baton Rouge (4%), Orleans (3%), and St. Mary (4%) are the parishes with the next highest number of load tests while the remainder of the parishes had 2% or less per parish.
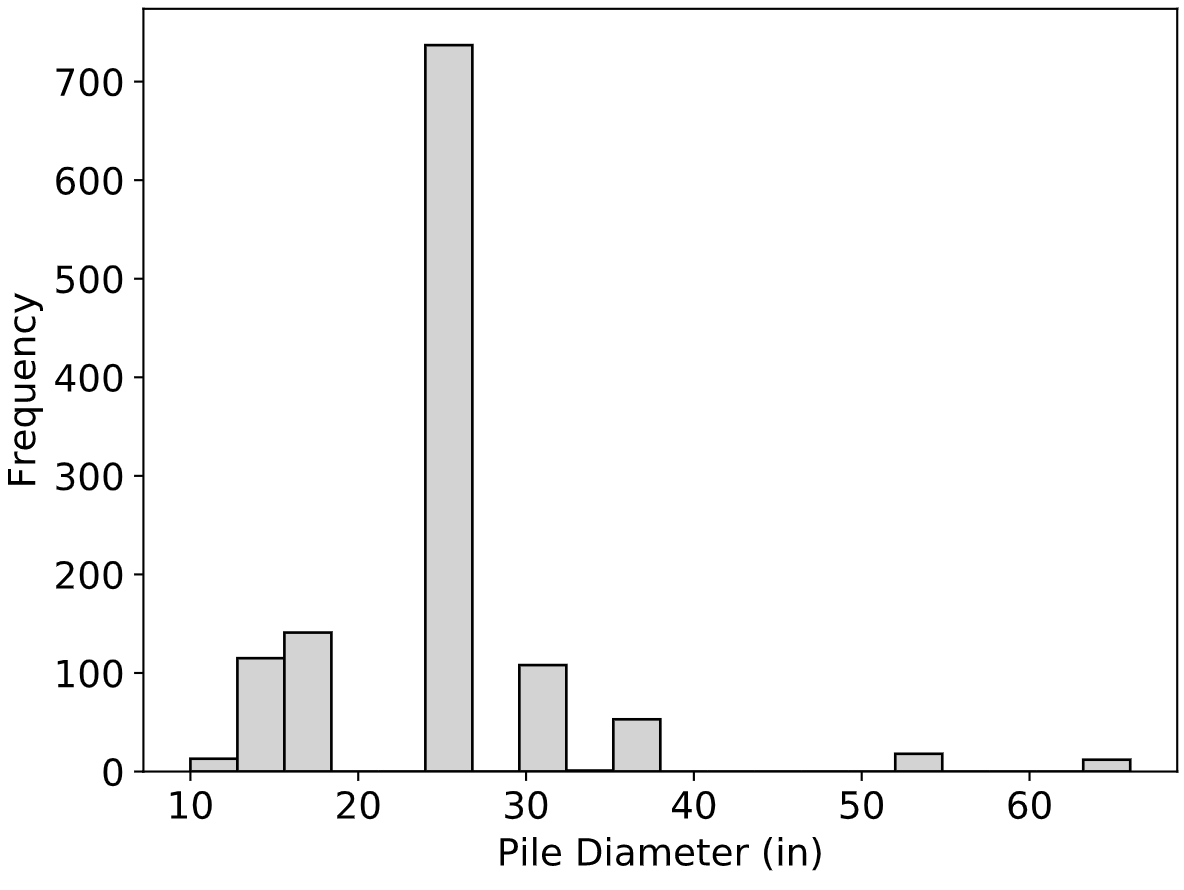
Fig. 2.17 Distribution of Pile Diameters in LTRC LAPLTD¶
There is no information on soil conditions within the dataset other than soil classification. LTRC Report 561 (Tavera et. al, 2016) mentioned that approximately 94% (1,112 load tests) of the database piles that were load tested were located in Quaternary soil deposits.
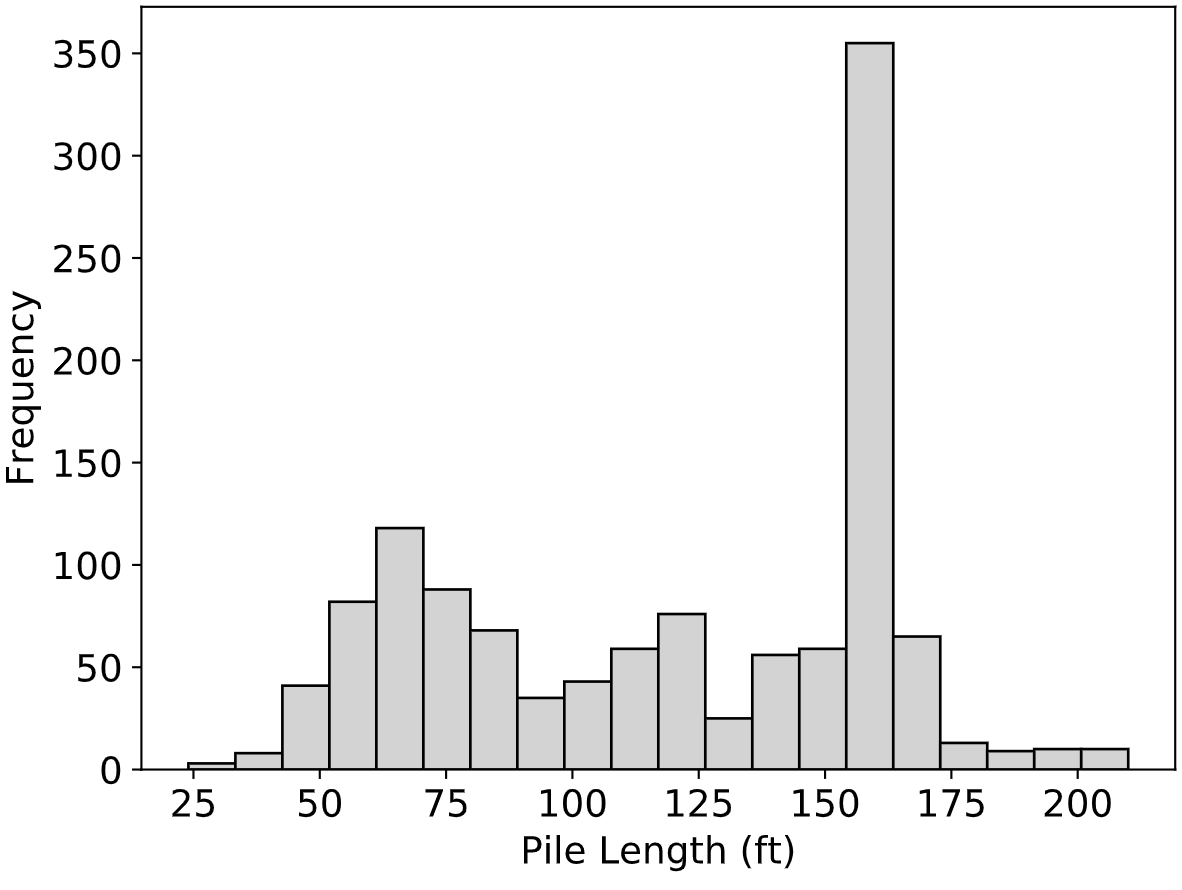
Fig. 2.18 Distribution of Pile Lengths in LTRC LAPLTD¶
LTRC Report 561 also noted that LTRC LAPLTD contained a total of 780 concrete piles and 23 steel piles, which translated to about 96% of all of the piles being Square Precast Pre-tensioned Concrete (PPC) Piles. This fact was verified when the data was ported in NYU Pile Capacity as shown in Fig. 2.16. The distribution of pile diameters from the records in LTRC LAPLTD is presented in Fig. 2.17 and the distribution of pile lengths is presented in Fig. 2.18. It is evident that the majority of the piles were 24-inch, 160-ft concrete piles.
2.2.4.3. Data Format and ETL¶
LTRC LAPLTD was implemented in Microsoft Access 2013. The author received a single MS Access file from Mr. Tavera, who was eager to describe the project and offer insights. The file did not contain any data on soil conditions and was also missing a table named dtWEAPModel for which the DDL code was defined. Data was organized in 17 tables. Tables with the prefix dt appeared to store the bulk of the information while tables with the prefix lst stored reference data that was not intended to be updated. Based on the DDL code extracted from the MS Access file, the ER diagram was constructed and is presented in Fig. 2.19. The design of the database did not appear to follow standard normalization rules.
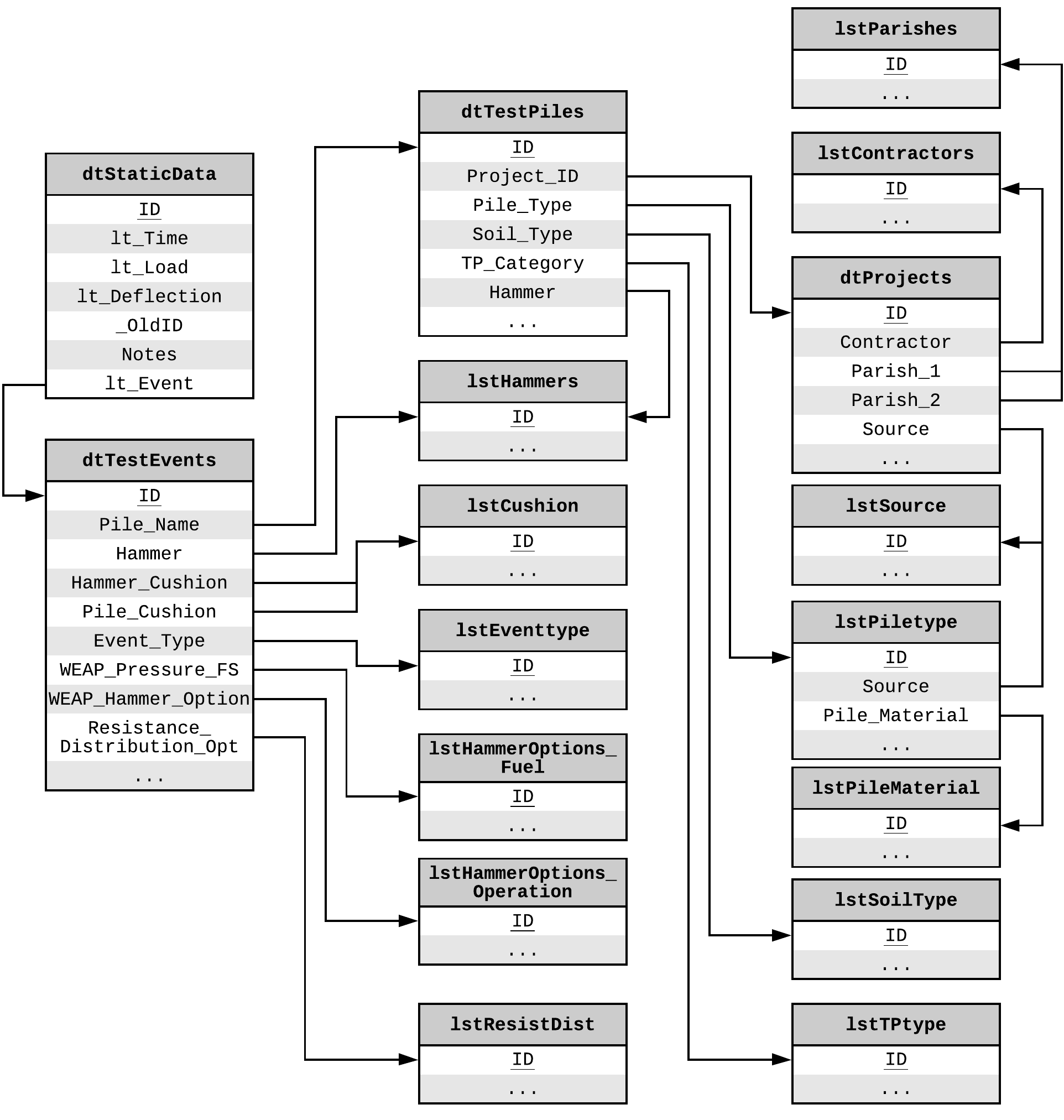
Fig. 2.19 E-R Diagram of LTRC LAPLTD¶
All tables were exported from the MS Access database in tabular format, specifically comma separated value (CSV) files. The ETL process was executed in Python by loading all CSV files and matching the columns of the tables to the attributes of the NYU Pile Capacity relational database. An object relational mapping (ORM) module was used to load the data into the database. The process was straightforward, without major unit conversions and was based on the table dtTestEvents which appeared to be the main table of LTRC LAPLTD. The code for this ETL process is presented in Listing 2.6. Description of the original attributes as well as mapping to the new attributes is detailed in section LAPLTD Tables and Attributes in the Appendix.
# -- Imports ---------------------------------------------------------------- #
import os
import pandas as pd
from tqdm import tqdm
from app import db
from .aux import data_owner
from app.models import Locations, Projects, Piles, LoadTests, StaticTests, \
InterpCapacities, Borings
# -- File Paths ------------------------------------------------------------- #
LAPTLD_DATA_DIR = os.path.join('app', 'etl', '_data_sources', 'lapltd')
dt_projects_path = os.path.join(LAPTLD_DATA_DIR, 'dtProjects.txt')
dt_staticdata_path = os.path.join(LAPTLD_DATA_DIR, 'dtStaticData.txt')
dt_testevents_path = os.path.join(LAPTLD_DATA_DIR, 'dtTestEvents.txt')
dt_testpiles_path = os.path.join(LAPTLD_DATA_DIR, 'dtTestPiles.txt')
lst_parishes_path = os.path.join(LAPTLD_DATA_DIR, 'lstParishes.txt')
lst_contractors_path = os.path.join(LAPTLD_DATA_DIR, 'lstContractors.txt')
lst_piletype_path = os.path.join(LAPTLD_DATA_DIR, 'lstPileType.csv')
# -- Creating Pandas DataFrames --------------------------------------------- #
dt_projects = pd.read_csv(dt_projects_path)
dt_staticdata = pd.read_csv(dt_staticdata_path)
dt_testevents = pd.read_csv(dt_testevents_path)
dt_testpiles = pd.read_csv(dt_testpiles_path)
lst_parishes = pd.read_csv(lst_parishes_path)
lst_contractors = pd.read_csv(lst_contractors_path)
lst_piletype = pd.read_csv(lst_piletype_path)
# -- Helper Functions ------------------------------------------------------- #
def add_loc_proj(prj_id, pile_id):
""" Compiles location and project data given an index for the tbl_project
DataFrame
"""
# -- Adding Location Data ----------------------------------------------- #
parish_id = int(dt_projects['Parish_1'][dt_projects.ID == prj_id])
parish = lst_parishes['Parish_Name'][lst_parishes.ID == parish_id].values[0]
lat = dt_testpiles['Latitude'][dt_testpiles.ID == pile_id].values[0]
lon = dt_testpiles['Longitude'][dt_testpiles.ID == pile_id].values[0]
loc = Locations(
county=parish,
state='Louisiana',
country='USA',
latitude=lat,
longitude=lon
)
db.session.add(loc)
# -- Adding Project Data ------------------------------------------------ #
contr_id = int(dt_projects['Contractor'][dt_projects.ID == prj_id])
contractor = lst_contractors['Contractor'][
lst_contractors.ID == contr_id].values[0]
source_ref = 'From: {}'.format(
source_dic[dt_projects['Source'][dt_projects.ID == prj_id].values[0]])
number = '{}; {}'.format(
dt_projects['Project_Num_H'][dt_projects.ID == prj_id].values[0],
dt_projects['Project_Num_old'][dt_projects.ID == prj_id].values[0])
prj = Projects(
location=loc,
user_id=data_owner().id,
source_db='LTRC LAPLTD',
source_id=prj_id,
source_ref=source_ref,
number=number,
title=dt_projects['Project_Name'][dt_projects.ID == prj_id].values[0],
site_name=dt_projects['Route'][dt_projects.ID == prj_id].values[0] if
not pd.isna(dt_projects['Route'][dt_projects.ID == prj_id].values[0])
else None,
contractor=contractor
)
return prj
def add_pile_data(pile_id, prj):
""" Compiles the pile data
"""
ptype_id = dt_testpiles['Pile_Type'][dt_testpiles.ID == pile_id].values[0]
ptype = lst_piletype['Pile_Type'][lst_piletype.ID == ptype_id].values[0]
shape = lst_piletype['Pile_Shape'][lst_piletype.ID == ptype_id].values[0] \
if not pd.isna(
lst_piletype['Pile_Shape'][lst_piletype.ID == ptype_id].values[0]) \
else None
diam = lst_piletype['Diam_Pile'][lst_piletype.ID == ptype_id].values[0] \
if not pd.isna(
lst_piletype['Diam_Pile'][lst_piletype.ID == ptype_id].values[0]) \
else None
dvoid = lst_piletype['Diam_Void'][lst_piletype.ID == ptype_id].values[0] \
if not pd.isna(
lst_piletype['Diam_Void'][lst_piletype.ID == ptype_id].values[0]) \
else None
thickness = (diam - dvoid)/2 if dvoid else None
circ = lst_piletype['Perimeter'][lst_piletype.ID == ptype_id].values[0]/12 \
if not pd.isna(
lst_piletype['Perimeter'][lst_piletype.ID == ptype_id].values[0]) \
else None
scirc = lst_piletype['HP Box Perimeter'][
lst_piletype.ID == ptype_id].values[0]/12 if not pd.isna(
lst_piletype['HP Box Perimeter'][
lst_piletype.ID == ptype_id].values[0]) else None
area = lst_piletype['Area_Gross'][lst_piletype.ID == ptype_id].values[0] \
if not pd.isna(
lst_piletype['Area_Gross'][lst_piletype.ID == ptype_id].values[0]) \
else None
pile = Piles(
project=prj,
type=ptype,
shape=shape,
diameter=diam,
wall_thickness=thickness,
circumference=circ,
square_circ=scirc,
cross_area=area,
name=dt_testpiles['Pile_Name'][dt_testpiles.ID == pile_id].values[0],
date_driven=pd.to_datetime(
dt_testpiles['Date_Driven'][
dt_testpiles.ID == pile_id].values[0]),
length=dt_testpiles['Length'][dt_testpiles.ID == pile_id].values[0],
remarks=dt_testpiles['Notes'][dt_testpiles.ID == pile_id].values[0]
if not pd.isna(
dt_testpiles['Notes'][dt_testpiles.ID == pile_id].values[0])
else None,
modulus=dt_testpiles['Modulus'][
dt_testpiles.ID == pile_id].values[0] if not pd.isna(
dt_testpiles['Modulus'][dt_testpiles.ID == pile_id].values[0])
else None,
design_load=dt_testpiles['Load_Design'][
dt_testpiles.ID == pile_id].values[0] * 2 if not pd.isna(
dt_testpiles['Load_Design'][dt_testpiles.ID == pile_id].values[0])
else None
)
return pile
def add_boring_data(pile_id, prj):
""" Compiles the few available boring data
"""
near_bor = dt_testpiles['Near_Boring'][
dt_testpiles.ID == pile_id].values[0] if not pd.isna(
dt_testpiles['Near_Boring'][dt_testpiles.ID == pile_id].values[0]) \
else None
near_cpt = dt_testpiles['Near_CPT'][
dt_testpiles.ID == pile_id].values[0] if not pd.isna(
dt_testpiles['Near_CPT'][dt_testpiles.ID == pile_id].values[0]) \
else None
if near_bor and not near_cpt:
bor_name = near_bor
elif not near_bor and near_cpt:
bor_name = near_cpt
elif not near_bor and not near_cpt:
bor_name = None
else:
bor_name = near_bor + '; ' + near_cpt
boring = Borings(
project=prj,
name=bor_name,
predom_soil=soil_dict[dt_testpiles['Soil_Type'][
dt_testpiles.ID == pile_id].values[0]] if not pd.isna(
dt_testpiles['Soil_Type'][dt_testpiles.ID == pile_id].values[0]
) else None,
elevation=dt_testpiles['Elev_GS'][dt_testpiles.ID == pile_id].values[0]
)
return boring
def add_static_test_data(test_event_id, load_test):
""" Compiles the static test data
"""
slt_points = dt_staticdata[dt_staticdata.lt_Event == test_event_id]
i_lt = 1
for i in slt_points.index:
slt = StaticTests(
load_test=load_test,
index=i_lt,
load=slt_points['lt_Load'][i] * 2,
displacement=slt_points['lt_Deflection'][i]
)
i_lt += 1
db.session.add(slt)
def add_interp_data(i, load_test):
""" Compiles the interpreted capacity data
"""
load = dt_testevents['Capacity_Ult'][i] * 2 \
if not pd.isna(dt_testevents['Capacity_Ult'][i]) else None
if load:
method = dt_testevents['Ult_Cap_Method'][i] if not \
pd.isna(dt_testevents['Ult_Cap_Method'][i]) else None
if method == 'Davisson':
method = 'Standard Davisson'
elif method is None:
method = 'Unknown/Not Specified'
capacity = InterpCapacities(
load_test=load_test,
load=load,
type=method,
origin='source DB'
)
db.session.add(capacity)
# -- Main Import Function --------------------------------------------------- #
def load_lapltd_records():
""" Iterates through source files and adds the LTRC LAPLTD records to the
database
"""
print('--- Importing LTRC LAPLTD records ---')
for i in tqdm(range(len(dt_testevents))):
test_event_id = int(dt_testevents['ID'][i])
pile_id = int(dt_testevents['Pile_Name'][i])
prj_id = int(dt_testpiles['Project_ID'][dt_testpiles.ID == pile_id])
# print(test_event_id, 'Project ID:', prj_id, 'Pile_ID:', pile_id)
# -- Adding Project Data -------------------------------------------- #
prj = add_loc_proj(prj_id, pile_id)
db.session.add(prj)
# -- Adding Pile Data ----------------------------------------------- #
pile = add_pile_data(pile_id, prj)
db.session.add(pile)
# -- Adding Boring Data --------------------------------------------- #
boring = add_boring_data(pile_id, prj)
db.session.add(boring)
# -- Adding Load Test Data ------------------------------------------ #
load_test = LoadTests(
pile=pile,
direction=lt_dir[dt_testevents['Event_Type'][i]],
remarks=dt_testevents['Notes'][i]
if not pd.isna(dt_testevents['Notes'][i]) else None,
)
db.session.add(load_test)
# -- Adding Static Test Data ---------------------------------------- #
add_static_test_data(test_event_id, load_test)
# -- Adding Interpreted Data ---------------------------------------- #
add_interp_data(i, load_test)
db.session.commit()
2.3. Design and Development of NYU Pile Capacity¶
A quick observation from the previous section, Original Data Sources, is that all databases were distributed as standalone datasets or software applications that were intended to be be installed on a local computer. Any changes would only be saved locally making it very difficult to share data or collaborate. Also, Iowa PILOT and LTRC LAPLTD were the only databases with input forms that allowed for entry of new records. Lastly, and perhaps more importantly, with all existing pile load test databases there has been no consideration on useful data export or data connectors that would allow for a wide range of analyses on the entire dataset rather than a case-by-case basis. A major goal of NYU Pile Capacity was to address all of these shortcomings and offer features that align with the modern requirements for data analytics. At the same time NYU Pile Capacity was designed to be extensible in order to accommodate virtually unlimited data as well as additional methods of analysis.
Fig. 2.20 Presenting the first two records out of 7,511 in NYU Pile Capacity¶
At launch, NYU Pile Capacity stored geotechnical, pile and load test data for 7,511 records and can be accessed at http://pilecapacity.com. NYU Pile Capacity is a web application built on Python and Flask with a relational database (Postgres).
2.3.1. Unifying Database Schema¶
Database design is an iterative process. It involves multiple cycles of development and with each cycle the design is usually refined to better fit the project needs. The main objective for NYU Pile Capacity was to combine all four previously described databases in one relational database, transferring all information necessary for capacity and other engineering calculations. Out of the four source databases, the Olson APC database was the most concise and to-the-point collection of relevant data and it served as the basis for the design of NYU Pile Capacity’s schema that was then expanded to accommodate data from the other three sources. The Extract, Transform and Load (ETL) process for each data source was presented in the previous section and all attribute mappings are included in the Appendix.
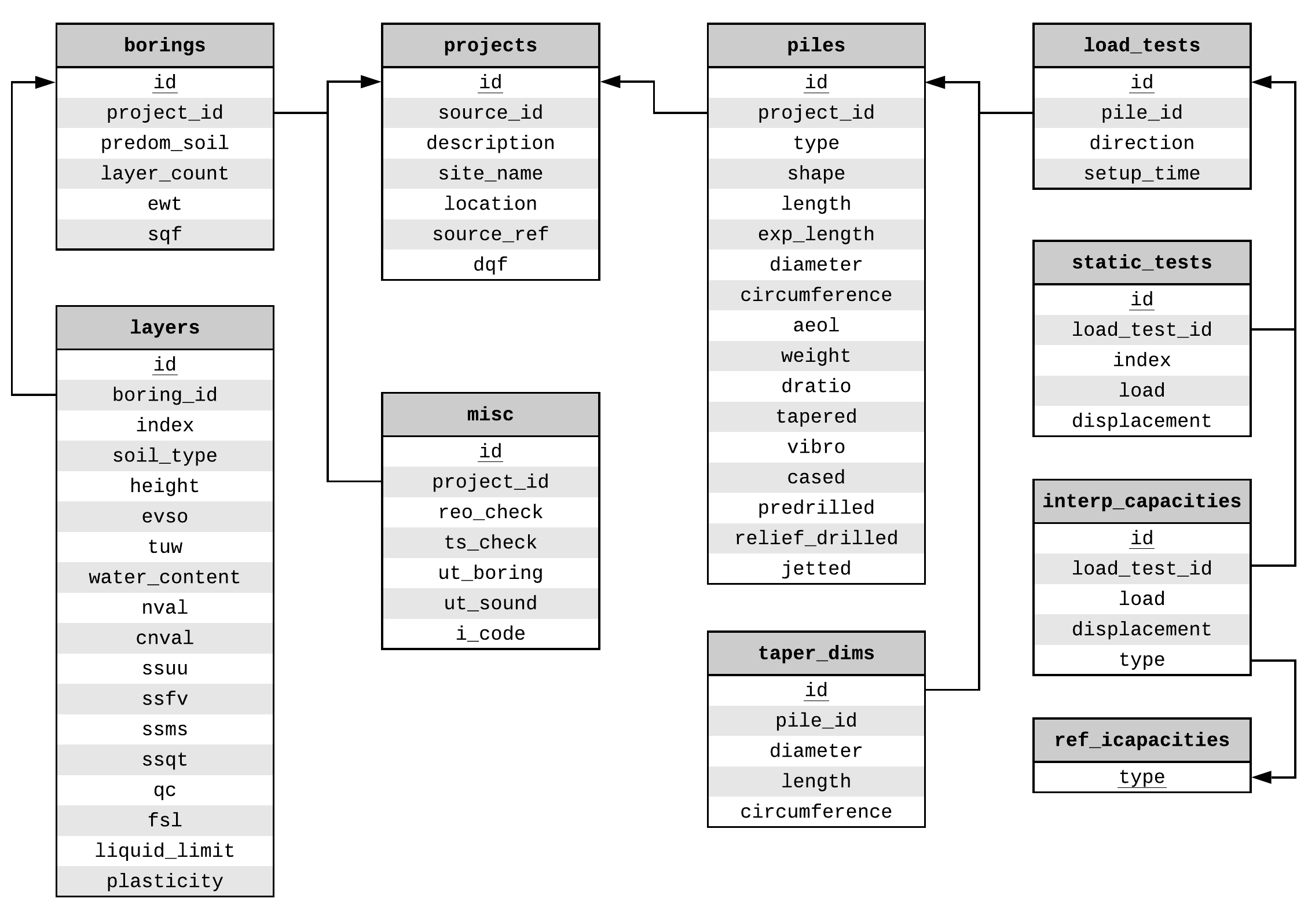
Fig. 2.21 Intermediate E-R Diagram of NYU Pile Capacity after defining the database attributes from the Olson APC Database raw files¶
Table 8 (appendix) summarizes the variables available in the Olson APC Database raw data files. The reduction of these variables to a relational schema is presented in Fig. 2.21. This resulted in 10 tables and 75 attributes. It is important to note that in this first iteration, normalization rules are not strictly enforced, although the goal was to make the schema adhere to 3rd Normal Form (3NF). For instance, attributes ssuu, ssfv, ssms, ssqt are all storing information on shear strength obtained from different tests and it could be argued that they are violating the “non-repeating attribute” rule of the 1st Normal Form (1NF). However, in the context of geotechnical engineering, it is unlikely that a value for shear stregth obtained from a new lab test will need to be stored. It is also unlikely that multiple values of shear strength from the same lab test will need to be stored for a single layer. As such, it is far more practical to keep these four attributes in the layers relation than move them in separate relations in order to be strictly compliant with the normalization process.
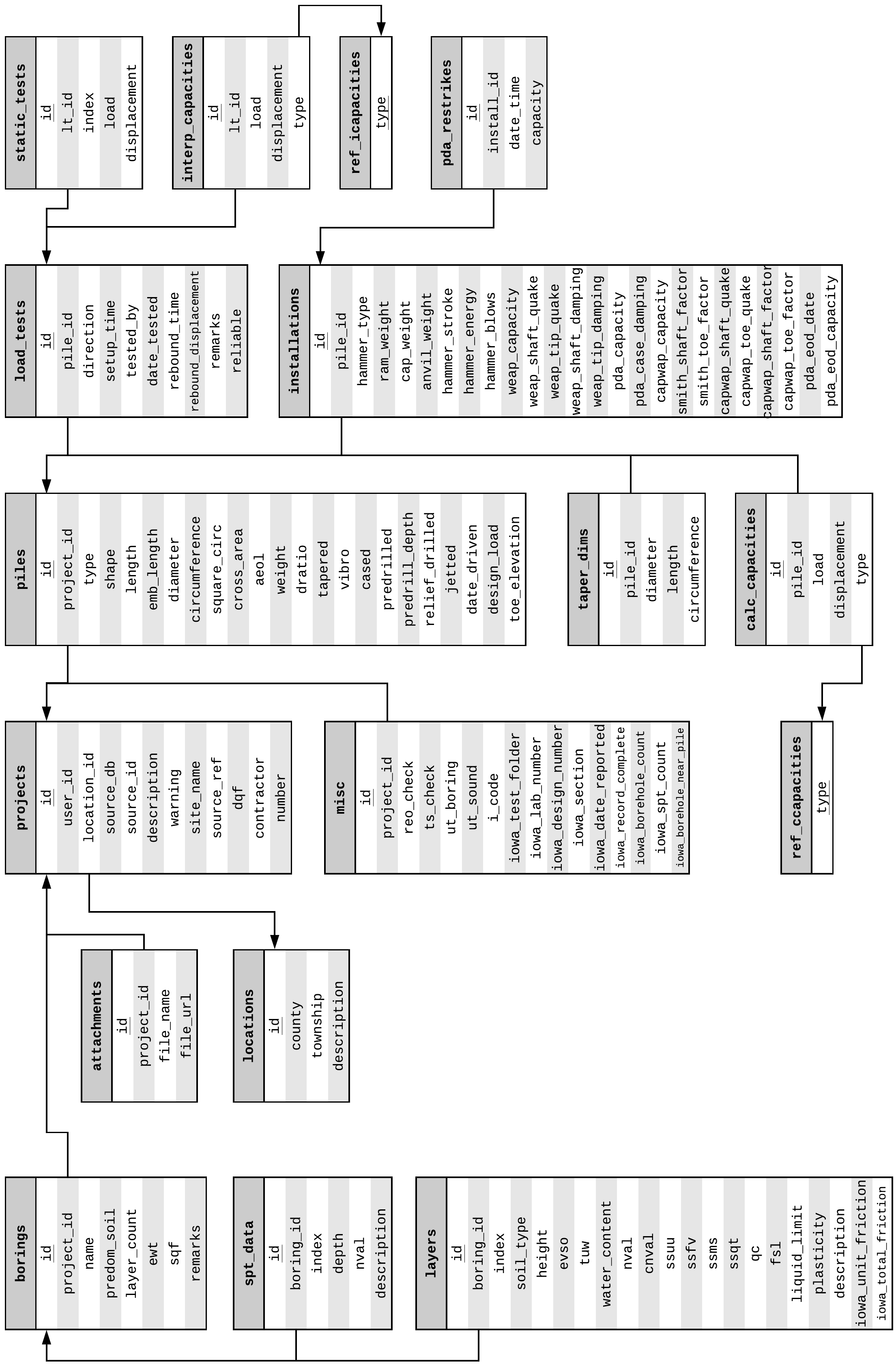
Fig. 2.22 Intermediate E-R Diagram of NYU Pile Capacity after defining the database attributes from the Olson APC Database raw files and mapping the Iowa PILOT database attributes¶
With the Olson APC ETL process complete, the next data source to be processed was Iowa PILOT. Every attribute from Iowa PILOT was mapped and the database for NYU Pile Capacity was expanded as shown in Fig. 2.22. The resulting database included 17 tables and 156 attributes.
The next data source that was processed was FHWA DFLTD v.2. This was also the most complex ETL process as evident in Listing 2.5. It was important to maintain the simple and straightforward structure of the NYU Pile Capacity database. The reason for that was to allow for the unified database to be queried directly from users with SQL code and to enable efficient interactions with interactive reporting solutions such as Tableau and Metabase. As such, while the E-R diagrams for NYU Pile Capacity show one-to-many relationships for all tables, in reality most relationships are intended to be one-to-one. This was enforced on the application and not the database level. Write/alter actions were implemented only via the online user interface. Any direct query operations were and will be read-only with dedicated user accounts. For instance, a project may only have one associated boring record, one pile record and one load test record. However, multiple capacity values can be entered for a pile and a boring record may have multiple soil layers.
Fig. 2.23 Final E-R Diagram of NYU Pile Capacity¶
The final E-R diagram for NYU Pile Capacity, after porting FHWA DFLTD v.2 and LTRC LAPLTD is presented in Fig. 2.23. It included 19 tables and 158 attributes. Of particular importance were tables calc_capacities and interp_capacities with their corresponding reference tabled (noted with the prefix ref_). The objective in this case was to allow for multiple calculated and interpreted capacity values to be stored along with their type and origin. For example, an calculated capacity based on the API method may have been imported from the original data source but another value based on the same method can be stored if it is the result of hand or programmatic calculations.
2.3.2. Operational Workflow¶
Drawing from the experience of using past load test databases, along with the inherent difficulties of scientific research, it was important that NYU Pile Capacity offers users the flexibility to interact with the load test records, collaborate with peers and share results. All projects (table projects, Fig. 2.24) in the database have an owner (table users, Fig. 2.24). That person can either be the one who imported the record in the database or the one who cloned an existing record, essentially making it their own. All users can view all records but owners can edit their own records only. The database keeps track of which records have been cloned with the clones relationship set, a self-referential, many-to-many table.
NYU Pile Capacity allows for analyses (table analyses, Fig. 2.24) on one or more stored projects (aggregate analyses). A user has the option to add one or more projects to an analysis. This is being handled by the projects_analyzed relationship set which defines a many-to-many relationship between projects and analyses. As shown in the partial E-R diagram of Fig. 2.24, a user can have multiple projects and multiple analyses, however a project or analysis may only have one user. This partial E-R diagram supplements the final E-R diagram presented in Fig. 2.23, note that the projects table is the same in both figures.
Fig. 2.24 NYU Pile Capacity: Partial E-R Diagram of Logical Workflow¶
Users may have one of three defined roles, or user-access levels: guest, standard or administrator. Once a new user signs up on NYU Pile Capacity, she is automatically assigned the guest role. This means that can browse through all records stored in the database and can also create and run new analyses. A guest user cannot import new records in the database. This is possible with the standard role. Still, standard users can only edit their own records. A guest user can have their user-access level changed by contacting the admins. Finally, a user with the administrator role can edit any record in the database, even ones that have been added by other users. While the database schema was designed to support all these interactions, the rules are enforced at the application level by limiting features to users based on their assigned role.
CREATE TABLE projects (
id serial
, user_id integer
, location_id integer
, source_db varchar(64)
, source_id smallint
, description text
, warning varchar(255)
, site_name varchar(128)
, source_ref text
, dqf smallint
, contractor varchar(255)
, number varchar(128)
, title varchar(255)
, date_added date
, date_modified date DEFAULT NOW()
, PRIMARY KEY (id)
, FOREIGN KEY (user_id) REFERENCES users (id),
, FOREIGN KEY (location_id) REFERENCES locations (id)
);
CREATE TABLE clones (
org_id integer
, new_id integer
, PRIMARY KEY (org_id, new_id)
, FOREIGN KEY (org_id) REFERENCES projects (id)
, FOREIGN KEY (new_id) REFERENCES projects (id)
);
One of the great advantages of storing data in relational databases is making use of the Structured Query Language (SQL) to slice, dice and query data in infinite ways. SQL is also used to define the tables in the database, this part of SQL being referred to as the Data Definition Language (DDL). Listing 2.7 shows a sample of the DDL defining the projects and clones tables of NYU Pile Capacity. The remaining tables were similarly defined. DDL sets the table names, attribute names, data types for attributes, as well as all necessary integrity constraints (i.e. primary & foreign keys, checks and NOT NULL).
class Projects(db.Model):
id = db.Column(db.Integer, primary_key=True)
user_id = db.Column(db.Integer, db.ForeignKey('users.id'))
location_id = db.Column(db.Integer, db.ForeignKey('locations.id'))
source_db = db.Column(db.String(64))
source_id = db.Column(db.SmallInteger)
description = db.Column(db.Text)
warning = db.Column(db.String(255))
site_name = db.Column(db.String(128))
source_ref = db.Column(db.Text)
dqf = db.Column(db.SmallInteger)
contractor = db.Column(db.String(255))
number = db.Column(db.String(128))
title = db.Column(db.String(255))
date_added = db.Column(db.Date)
date_modified = db.Column(db.DateTime, default=datetime.utcnow)
cloned = db.relationship(
'Projects', secondary=clones,
primaryjoin=(clones.c.org_id == id),
secondaryjoin=(clones.c.new_id == id),
backref=db.backref('clones', lazy='dynamic'), lazy='dynamic'
)
in_analyses = db.relationship(
'Analyses', secondary=projects_analyzed, lazy='dynamic')
misc = db.relationship('Misc', backref='project', lazy='dynamic')
attachments = db.relationship('Attachments', backref='project', lazy='dynamic')
borings = db.relationship('Borings', backref='project', lazy='dynamic')
piles = db.relationship('Piles', backref='project', lazy='dynamic')
def __repr__(self):
return '<Project ID: {}>'.format(self.id)
def clone(self, project):
if not self.is_cloned():
self.cloned.append(project)
def is_cloned(self):
return self.cloned.count() > 0
def make_qs_plot(self):
if self.piles.first().load_tests.first():
data = self.piles.first().load_tests.first().static_tests.all()
else:
data = None
return slt_plot_thumb(data)
clones = db.Table(
'clones',
db.Column('org_id', db.Integer, db.ForeignKey('projects.id'),
primary_key=True),
db.Column('new_id', db.Integer, db.ForeignKey('projects.id'),
primary_key=True),
)
SQL is great for direct database interactions. For example, users can pull data with SQL and analyze the data locally on their computers. And with more data added in the database, updating the analysis can be as simple as running the same code again. This functionality exists in NYU Pile Capacity, however, ETL and front-end interaction was based on an alternative method using SQLAlchemy (Bayer, 2012, https://www.sqlalchemy.org/). SQLAlchemy is a Python SQL toolkit and an Object Relational Mapper (ORM). ORMs represent relational tables as Python classes and their relationships are defined with SQLAlchemy methods. This translation from strict SQL to Python has the benefit of streamlining the development process while working with a coherent codebase. In addition, relational tables can have extended features by defining methods for their corresponding classes. For example, as can be seen in Listing 2.8, the make_qs_plot() method can query the database and plot the load/displacement thumbnail with a single command. This is an operation that would otherwise require several steps to complete.
2.3.3. Interface¶
NYU Pile Capacity was designed to be user friendly and extensible. The program has two main components:
Python Flask
Postgres Relational Database
An interaction flowchart is presented in Fig. 2.25. The first component, Python Flask, supports all front-end interactions (in other terms, the website served on http://pilecapacity.com) and all of the database connections the Postgres Database. Python Flask also allows for edafos to be loaded as an external module, run analyses on the data stored in the Postgres database and store the results into the database. edafos 1 is a separate Soil Mechanics Python module created by the author.
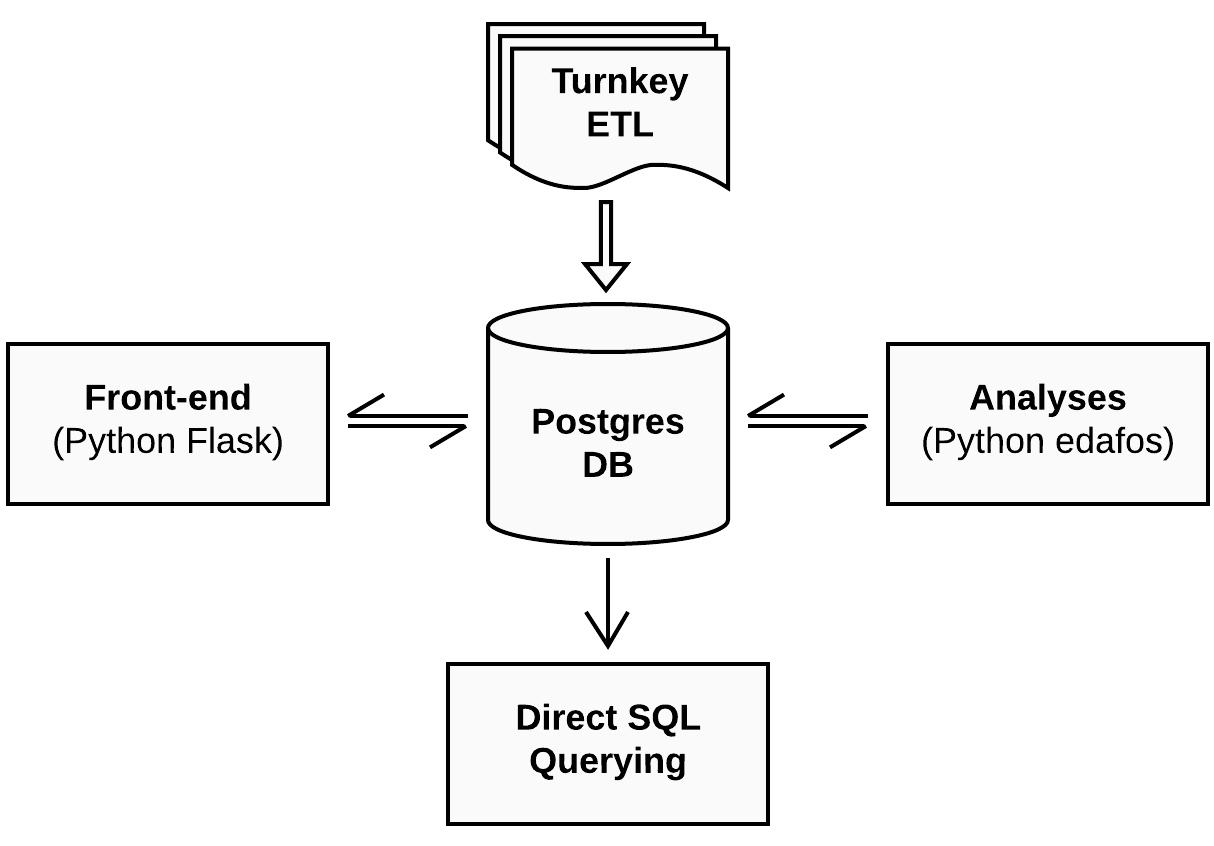
Fig. 2.25 NYU Pile Capacity: Component Interaction Flowchart¶
Loading all records from the source databases, a process that was described in the previous section, is noted on Fig. 2.25 as Turnkey ETL. This was a one-time operation that loaded all historical data into the database. In addition to front-end interactions with the database, users can also query the database directly using SQL.
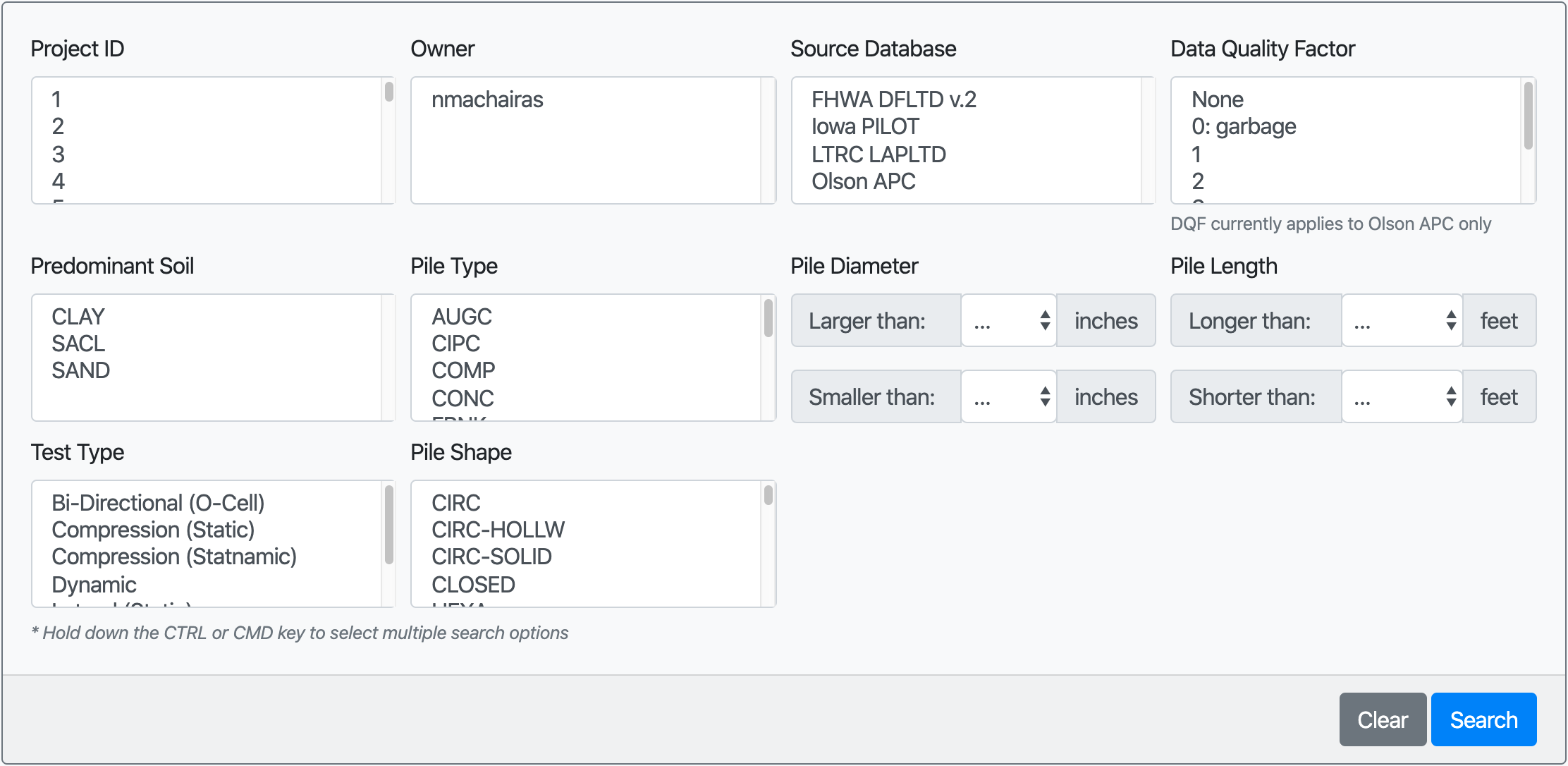
Fig. 2.26 NYU Pile Capacity Search Page¶
Users can browse through and use the historical data and/or add their own via the front-end interface. The search page of NYU Pile Capacity is shown in Fig. 2.26. It offers options to search based on records owners, sources databases, predominant soil conditions, pile type, shape, diameter, length as well as test type. The search results are displayed as cards (Fig. 2.27) and the user can quickly inspect some important properties, including the shape of the load test curve. The user can click on Details and review all values stored for a given record (Fig. 2.28 and Fig. 2.29) or add all search results to an aggregate analysis.
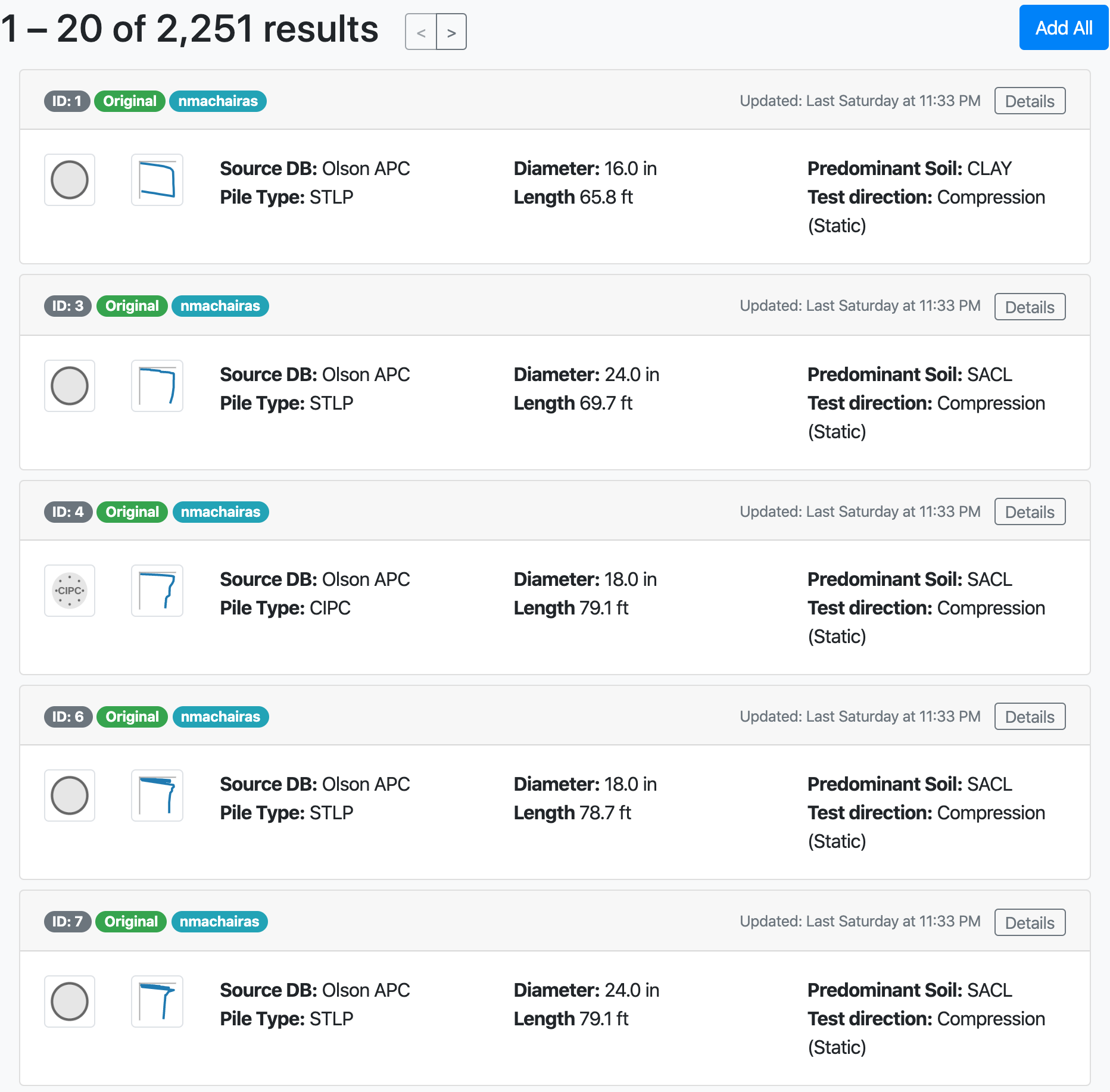
Fig. 2.27 NYU Pile Capacity: Example of Search Results¶
All search parameters are passed to the page url as request arguments. This can be a convenient way of sharing custom searches, simply by copying the link generated. For example, the url for a search query for records from the Iowa PILOT and Olson APC sources, in predominantly sandy soils and with piles wider than 16 inches would be, http://pilecapacity.com/search?source_db=Iowa+PILOT&source_db=Olson+APC&soil_type=SAND&min_d=16.
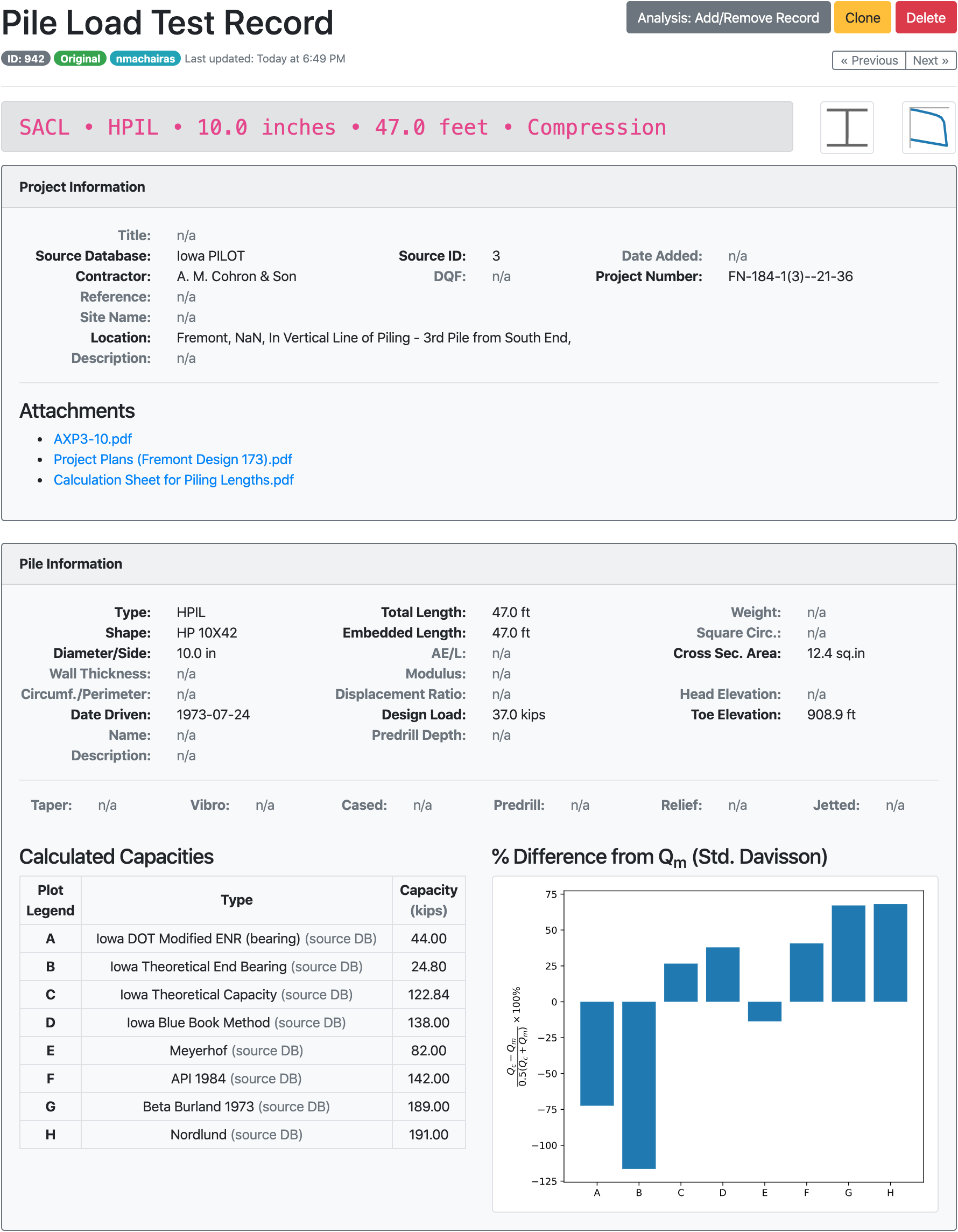
Fig. 2.28 NYU Pile Capacity: Example Record Page (1/2)¶
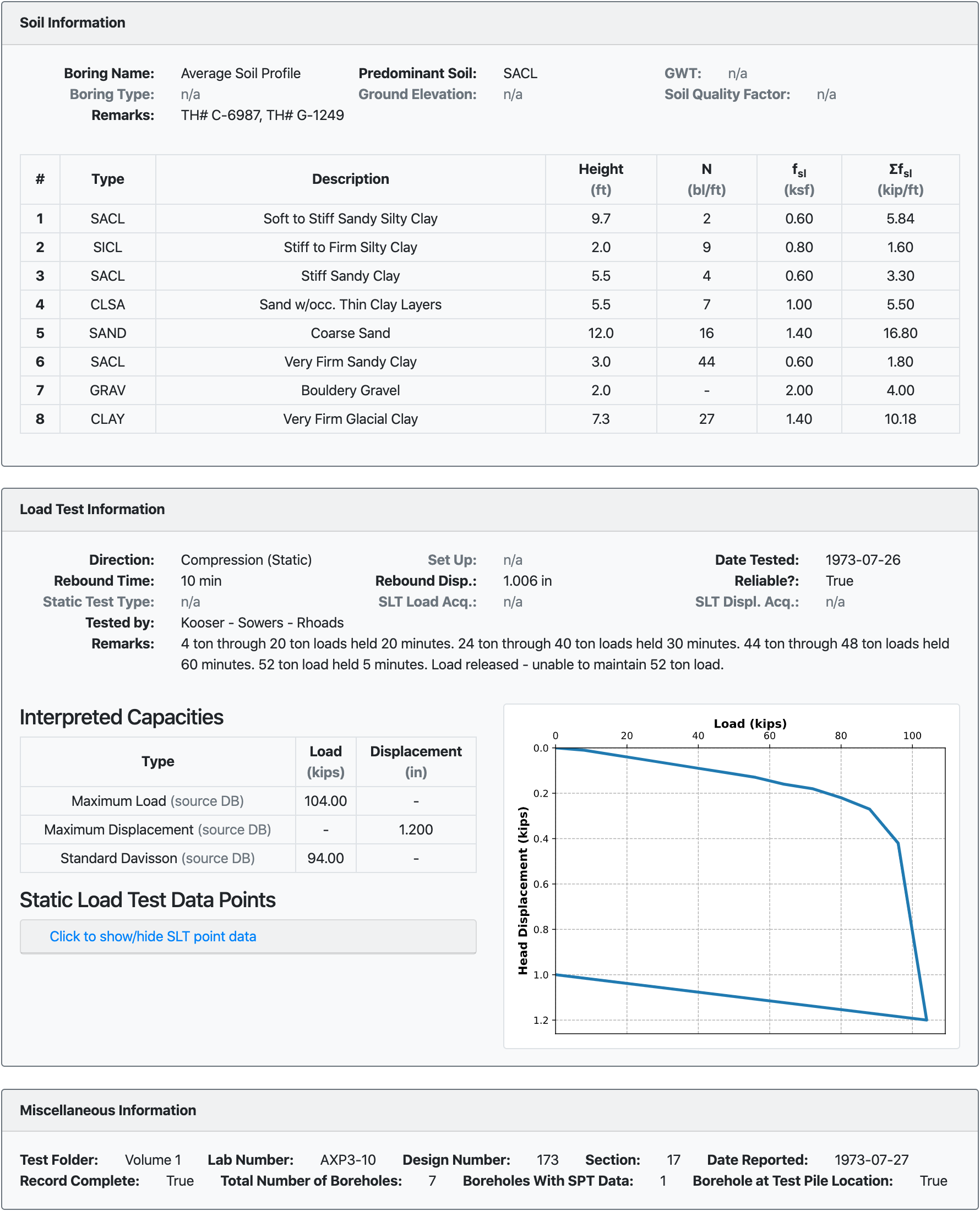
Fig. 2.29 NYU Pile Capacity: Example Record Page (2/2)¶
The option to create new analyses and records is available to users (access level Standard or higher) on the profile page. An example of a profile page is presented in Fig. 2.30. The profile page lists the analyses created by that user as well as other users analyses.
Fig. 2.30 NYU Pile Capacity: Profile Page¶
2.4. Case-Based Design¶
Running aggregate analyses was a core feature of NYU Pile Capacity and the flexibility of doing so on varying soil conditions and pile types opened up the possibility for a new approach to pile design, the case-based design of driven pile foundations.
Most of the existing design methods attempted to generalize and provide recommendations for all soil conditions and all pile types. There was, however, little focus on the performance of these methods for specific soil conditions and pile types. The industry implemented the design methods as blanket solutions expecting that they would perform well for all cases. NYU Pile Capacity provided the flexibility to run aggregate analyses on groups of load test records with similar characteristics.
Fig. 2.31 Example of case-based design of driven piles¶
In order to demonstrate this concept, an example load test record is shown in Fig. 2.31. The example involves a 51 ft long driven 10x42 H-Pile in mixed soil conditions. NYU Pile Capacity calculates capacities based on various design methods or uses the capacities as were reported from the original sources. For the case presented in Fig. 2.31, the Meyerhof method provided a capacity that was closer to the measured capacity from static load testing while the API 1984 method, a popular design method, provided a capacity that was more that 70% larger than the measured capacity.
The immediate observation was that for this specific case, Meyerhof was better than API 1984. However, this goes against common engineering practice and federal guidelines where it is recommended that Mayerhof should be used for preliminary design only. A question that had not been asked before was “Is it possible that Meyerhof performs well under certain conditions? And on the other end, is it possible that API does not perform well for certain conditions?”
A routine was programmed within NYU Pile Capacity that used the same methods for aggregate analyses but instead of the groups analysed being specified by the user, the program run analyses on groups of records with similar characteristics. For the example shown in Fig. 2.31, that would be a group of load test records of steel H-Piles, around 10 inches wide driven in mixed soil conditions.
Fig. 2.32 10-inch steel piles in mixed soils (case-based design of driven piles)¶
The results of the aggregate analysis (Meyerhof and API only) of 10-inch H-Piles in mixed soils are shown in Fig. 2.32. For comparison, the results of the aggregate analysis without this filtering are shown in Fig. 2.33. Note that this comparison was performed on a subset of the total load test records stored in NYU Pile Capacity.
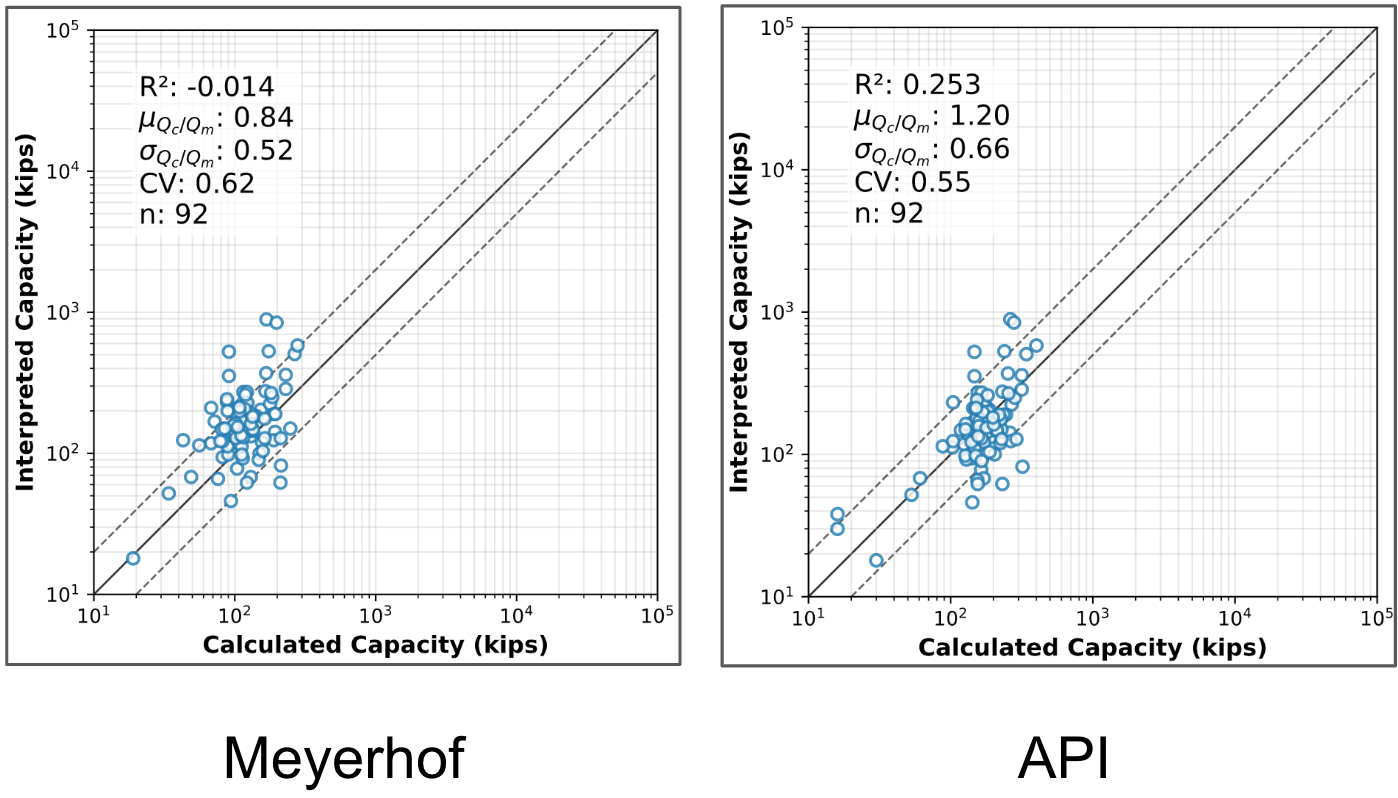
Fig. 2.33 No case filtering (case-based design of driven piles)¶
Focusing on the \(R^2\) score, Fig. 2.32 showed better performance for the API method than the Meyerhof method. A statement that also holds true for the analysis presented in Fig. 2.33. However, when comparing the two figures, Meyerhof seems to be performing a lot better for 10-inch H-Piles in mixed soils than it does for all piles, which could indicate the example record was not an outlier. At the same time, the poor performance of API on the example record was most likely an outlier.
Expanding this comparison from two design methods to multiple design methods and from one set of conditions to multiple sets of conditions can lead to gaining insights into the cases for which design methods perform best can enable enhanced pile design workflows where instead of using a single method to calculate capacities, a combination of methods can be employed depending on the soil conditions and pile type. Hence, case-based design can lead to safer and cost-effective designs for driven pile foundations.
